
MySQL笔记_2_基础_2
MySQL笔记_2_基础_2
1 MySQL 架构
1.1 MySQL 架构
MySQL 由连接池、SQL 接口、解析器、优化器、缓存、存储引擎等组成
可以分为四层:连接层、服务层、引擎层、文件系统层
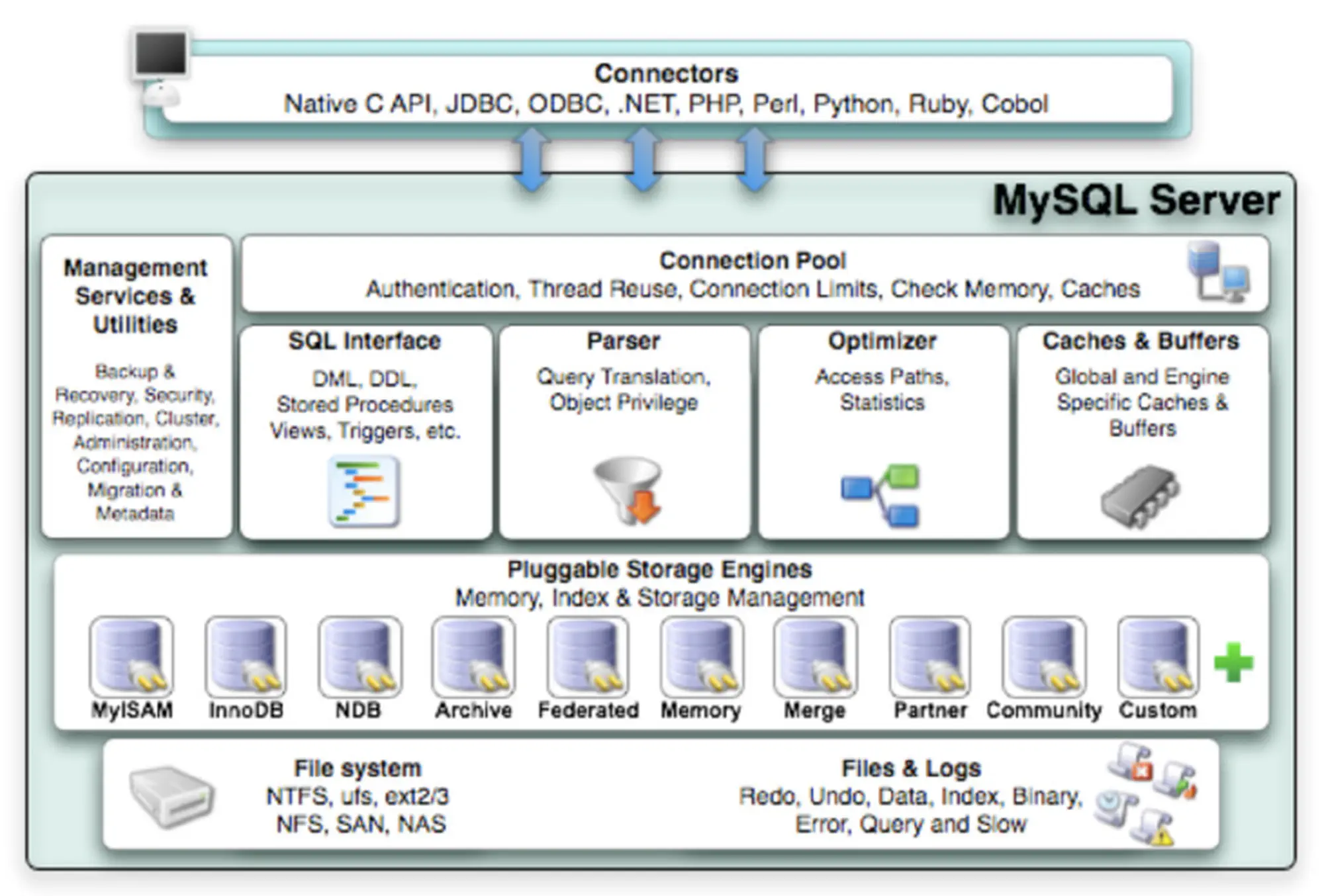
1.数据库架构)
连接层
- 最上面,是一些客户端和连接服务,不是MySQL特有的,所有基于网络的C/S的网络应用程序都应该包括连接处理、认证、安全管理等。
服务层(MySQL 的核心)
- 管理服务和工具
- 连接池
- SQL 接口(查询解析)
- 分析
- 优化
- 缓存
- 跨存储引擎的功能(存储过程、触发器、视图)
引擎层
- 存储引擎层
- 负责存取数据,服务器通过 API 和各种存储引擎进行交互
- 不同的存储引擎具有不同的功能,我们可以根据实际需求选择使用对应的存储引擎
文件系统层
- 数据存储层
- 主要是将数据存储在运行设备的文件系统之上,并完成与存储引擎的交互
1.2 SQL 查询流程
以一条 SQL SELECT 语句的执行轨迹来说明客户端与 MySQL 的交互过程
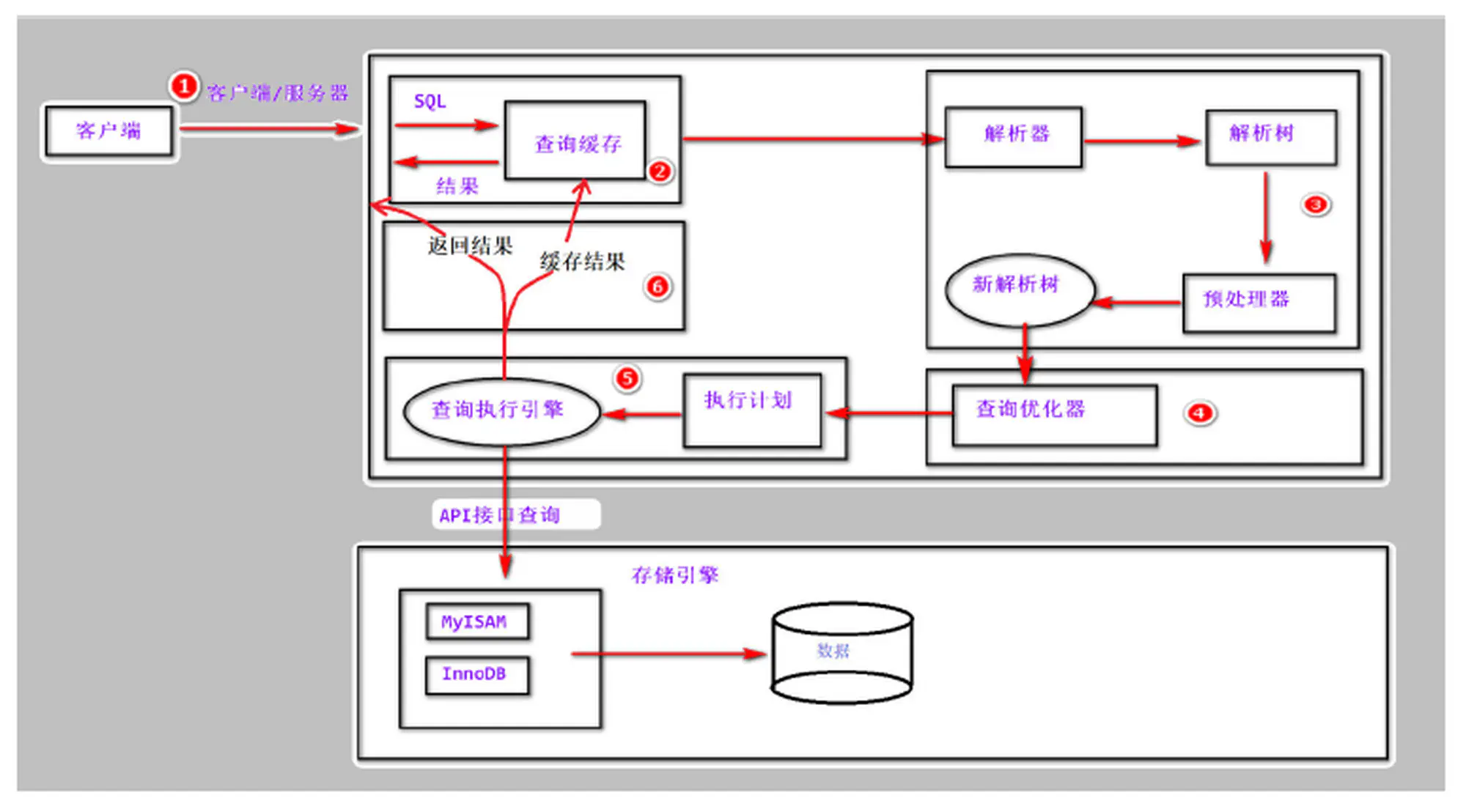
2.DQL 执行流程)- 通过客户端/服务器通信协议与 MySQL 建立连接
- 查询缓存,这是 MySQL 的一个可优化查询的地方,如果开启了 Query Cache 且在查询缓存过程中查询到完全相同的 SQL 语句,则将查询结果直接返回给客户端;如果没有开启 Query Cache 或者没有查询到完全相同的 SQL 语句则会由解析器进行语法语义解析,并生成解析树。
- 预处理器生成新的解析树。
- 查询优化器生成执行计划。
- 查询执行引擎执行 SQL 语句,此时查询执行引擎会根据 SQL 语句中表的存储引擎类型,以及对应的 API 接口与底层存储引擎缓存或者物理文件的交互情况,得到查询结果,由 MySQL Server 过滤后将查询结果缓存并返回给客户端。若开启了 Query Cache ,这时也会将 SQL 语句和结果完整地保存到 QueryCache 中,以后若有相同的 SQL 语句执行则直接返回结果。
1.3 MySQL 物理文件
1.3.1 日志文件
- error log
- 错误日志
- bin log
- 二进制日志
- 关于备份,增量备份,DDL,DML,DCL操作的记录
- Relay log
- 中继日志
- slow log
- 慢查询日志
- 用于调优,记录查询时间超过指定值的查询操作
|
|
1.3.2 配置文件:my.cnf
|
|
1.3.3 数据文件
|
|
- .frm 文件
- 每一个表都有一个以表名命名的 .frm 文件,与表相关的元数据(meta)信息都存放在此文件中,包括表结构的定义信息等。
- .MYD 文件
- myisam 存储引擎专用,存放 myisam 表的数据(data)
- 每一个 myisam 表都会有一个 .MYD 文件与之呼应,同样存放在所属数据库的目录下
- .MYI 文件
- 也是 myisam 存储引擎专用,存放 myisam 表的索引相关信息
- 每一个 myisam 表对应一个 .MYI 文件,其存放的位置和 .frm 及 .MYD 一样
- .ibd 文件
- 存放 innoDB 的数据文件(包括索引)。
- db.opt 文件
- 此文件在每一个自建的库里都会有,记录这个库的默认使用的字符集和校验规。
2 备份与恢复
2.1 按业务方式分类
- 完全备份
- 将数据库的全部信息进行备份,包括数据库的数据文件、日志文件,还需要备份文件的存储位置以及数据库中的全部对象和相关信息。
- 差异备份
- 备份从最近的完全备份后对数据所做的修改,备份完全备份后变化了的数据文件、日志文件以及数据库中其他被修改的内容。
- 增量备份
- 增量备份是指在一次全备份或上一次增量备份后,以后每次的备份只需备份与前一次相比增加或者被修改的文件。
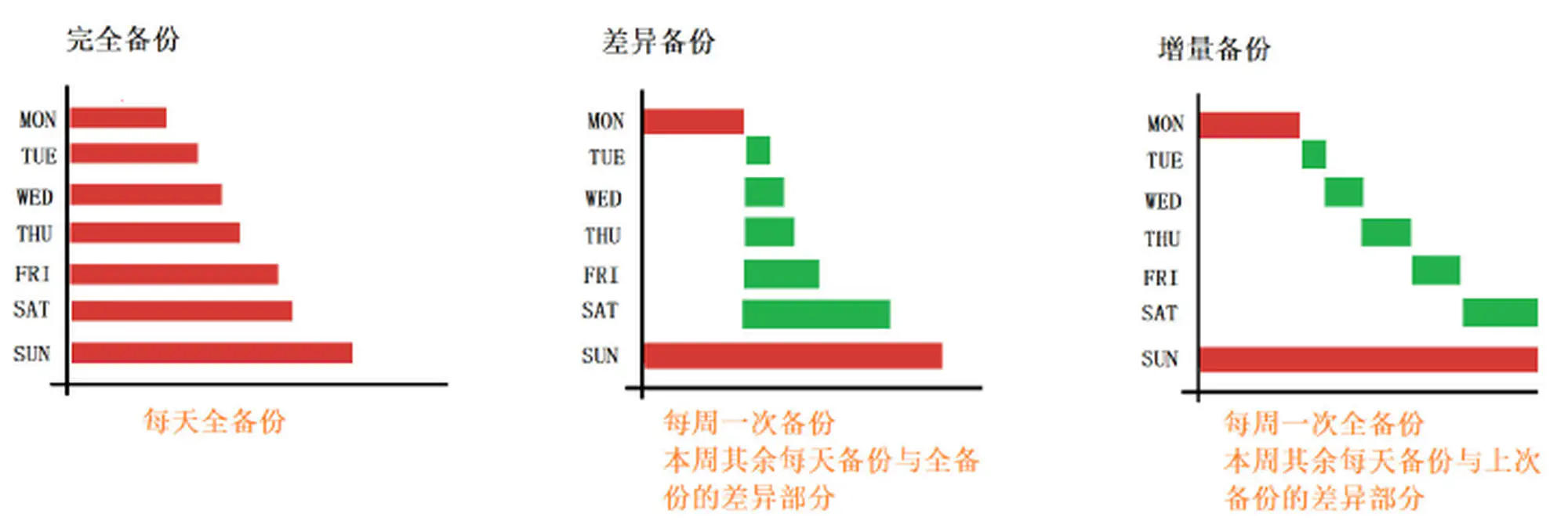
3.完全备份、差异备份、增量备份)| 完全备份 | 差异备份 | 增量备份 | |
|---|---|---|---|
| 备份方法 | 备份所有文件 | 一次全备份后 备份与全备份差异的部分 |
一次全备份后 备份与上次备份的差异部分 |
| 备份速度 | 最慢 | 较快 | 最快 |
| 恢复速度 | 最快 | 较快 | 最慢 |
| 存储空间占用 | 最多 | 较多 | 最少 |
| 优点 | 最快的恢复速度 只需要上一次完全备份就能恢复 |
相比增量,更快也更简单 恢复只需要最近一次的完全备份 和 最后一次的差异备份 |
备份速度快 较少的空间需求,没有重复的备份文件 |
| 缺点 | 最多的空间需求 大量重复的备份 |
较慢的备份速度 仍然会存在许多重复的备份文件 |
最慢的恢复速度 恢复需要最近一次完全备份 和 全部增量备份 |
2.2 按照运行状态分类
- 冷备份
- 冷备份指的是当数据库进行备份时,数据库不能进行读写操作,即数据库要下线
- 优点:
- 是操作比较方便的备份方法(只需拷贝文件)
- 低度维护,高度安全。
- 缺点:
- 在实施备份的全过程中,数据库不能作其它工作。
- 若磁盘空间有限,只能拷贝到磁带等其它外部存储设备上,速度比较慢慢。
- 不能按表或按用户恢复。
- 热备份
- 热备份是在数据库运行的情况下,备份数据库操作的 sql 语句,当数据库发生问题时,可以重新执行一遍备份的 sql 语句。
- 优点:
- 可在表空间或数据文件级备份,备份时间短。
- 备份时数据库仍可使用。
- 可达到秒级恢复(恢复到某一时间点上)。
- 缺点:
- 不能出错,否则后果严重。
- 因难维护,所以要特别仔细小心
2.3 冷备份实践:
先确定数据文件所在目录
|
|
|
|
2.4 热备份实践:
mysqldump 备份工具,是MySQL数据库用来备份和数据转移的一个工具,适用于数据量比较小的场景(几个G)。
热备份可以对多个库进行备份,也可以对单张表或者某几张表进行备份。
2.4.1 备份整库:
|
|
模拟数据丢失:
|
|
恢复数据:
|
|
也可以直接在 MySQL-Shell 中恢复
|
|
2.4.2 备份并压缩:
|
|
2.4.3 备份指定的表:
|
|
模拟数据丢失:
|
|
恢复数据:
|
|
2.5 使用 SQLYog(热备份)
- 备份
- 选中 “目标数据库”
- 右键,“备份/导出”
- “备份数据库……”
- 指定导出位置
- 恢复
- 选中 “数据库节点”
- 右键,“执行SQL脚本”
3 DCL 用户及权限管理
MySql默认使用的都是 root 用户,超级管理员,拥有全部的权限。除了root用户以外,我们还可以通过DCL语言来定义一些权限较小的用户, 分配不同的权限来管理和维护数据库。
-
创建用户
-
1CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
-
-
用户授权
-
1GRANT 权限 1, 权限 2... ON 数据库名.表名 TO '用户名'@'主机名';
-
-
查看权限
-
1SHOW GRANTS FOR '用户名'@'主机名';
-
-
删除用户
-
1DROP USER '用户名'@'主机名';
-
-
查询用户
-
1SELECT * FROM USER;
-
|
|
4 MySQL 索引、视图、存储过程、触发器
4.1 索引
- 在数据库表中,对字段建立索引可以大大提高查询速度。通过善用这些索引,可以令 MySQL 的查询和运行更加高效。
- 拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字
- MySql 将一个表的索引都保存在同一个索引文件中,如果对中数据进行增删改操作,MySql 都会自动的更新索引
4.1.1 存放索引的文件
MySql 将一个表的索引都保存在同一个索引文件中,如果对中数据进行增删改操作,MySql 都会自动的更新索引.
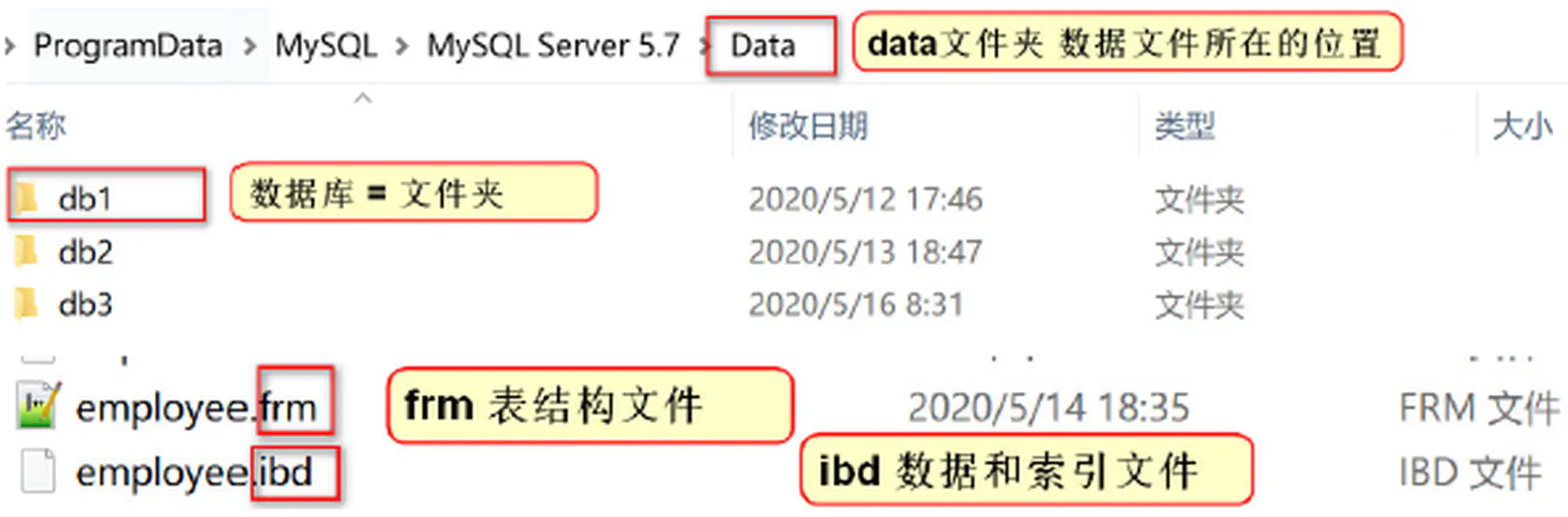
4.索引文件)
4.1.2 主键索引(primary key)
-
参考主键约束
-
主键是一种唯一性索引,每个表只能有一个主键,用于标识数据表中的每一条记录
-
创建表的时候直接添加主键索引(最常用)
-
1 2 3 4CREATE TABLE 表名( -- 添加主键 (主键是唯一性索引,不能为null,不能重复,) 字段名 类型 PRIMARY KEY, );
-
-
修改表结构,添加主键索引
-
1ALTER TABLE 表名 ADD PRIMARY KEY (列名)
-
|
|
4.1.3 唯一索引(unique)
-
参考唯一约束
-
唯一索引指的是 索引列的所有值都只能出现一次, 必须唯一
-
唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
-
创建表的时候直接添加主键索引
-
1 2 3 4 5CREATE TABLE 表名( 列名 类型(长度), -- 添加唯一索引 UNIQUE [索引名称] (列名) );
-
-
使用 create 语句创建:在已有的表上创建索引
-
1create unique index 索引名 on 表名(列名(长度))
-
-
修改表结构添加索引
-
1ALTER TABLE 表名 ADD UNIQUE ( 列名 )
-
|
|
4.1.4 普通索引 (index)
-
最常见的索引,作用就是加快对数据的访问速度
-
普通索引(由关键字 KEY 或 INDEX 定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHERE column = )或排序条件(ORDER BY column)中的数据列创建索引。
-
使用 create index 语句创建:在已有的表上创建索引
-
1create index 索引名 on 表名(列名[长度])
-
-
修改表结构添加索引
-
1ALTER TABLE 表名 ADD INDEX 索引名 (列名)
-
|
|
4.1.5 删除索引
-
由于索引会占用一定的磁盘空间,因此,为了避免影响数据库的性能,应该及时删除不再使用的索引
-
1ALTER TABLE table_name DROP INDEX index_name;
-
|
|
4.1.6 索引对数据库的读性能的提升测试
|
|
4.1.7 小结
- 添加索引首先应考虑在 where 及 order by 涉及的列上建立索引。
- 索引的优点
- 大大的提高查询速度
- 可以显著的减少查询中分组和排序的时间。
- 通过创建唯一索引保证数据的唯一性
- 索引的缺点
- 创建索引和维护索引需要时间,而且数据量越大时间越长
- 当对表中的数据进行增加,修改,删除的时候,索引也要同时进行维护,降低了数据的维护速度
- 索引文件需要占据磁盘空间
4.2 视图
- 视图是一种虚拟表。
- 视图建立在已有表的基础上,视图赖以建立的这些表称为基表。
- 向视图提供数据内容的语句为 SELECT 语句,可以将视图理解为存储起来的 SELECT 语句
- 视图向用户提供基表数据的另一种表现形式
4.2.1 作用
- 权限控制时可以使用
- 比如,某几个列可以运行用户查询,其他列不允许,可以开通视图查询特定的列,起到权限控制的作用
- 简化复杂的多表查询
- 视图本身就是一条查询 SQL ,我们可以将一次复杂的查询构建成一张视图,用户只要查询视图就可以获取想要得到的信息(不需要再编写复杂的 SQL )视图主要就是为了简化多表的查询
- 可以把常用的查询,多次使用的子查询建立视图,以提高效率
4.2.2 使用
-
创建视图
-
1 2 3 4 5create view 视图名 [column_list] as select语句; view: 表示视图 -- column_list: 可选参数,表示属性清单,指定视图中各个属性的名称,默认情况下,与SELECT语句中查询的属性相同 as : 表示视图要执行的操作 select 语句: 向视图提供数据内容 -
1 2 3 4 5 6 7 8 9 10-- 创建视图 -- 1.查询所有商品和商品对应分类的信息 SELECT * FROM products p LEFT JOIN category c ON p.`category_id` = c.`cid`; -- 2.根据上面的查询语句 构建一张视图 CREATE VIEW products_category_view AS SELECT * FROM products p LEFT JOIN category c ON p.`category_id` = c.`cid`; -- 操作视图 就相当于操作一张 只读表 SELECT * FROM products_category_view;
-
-
查询视图
-
当做一张只读的表操作就可以
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55-- 使用视图进行查询操作 -- 查询各个分类下的商品平均价格 /* 1.查询哪些表 分类表 商品表 2.查询条件是什么 分组操作 3.要查询的字段 平均价格,分类名 4.多表的连接条件 category_id = cid */ -- 使用多表方式查询 SELECT c.`cname`, AVG(p.`price`) FROM products p LEFT JOIN category c ON p.`category_id` = c.`cid` GROUP BY c.`cname`; -- 通过视图查询 SELECT pc.`cname`, AVG(pc.`price`) FROM products_category_view pc GROUP BY pc.`cname`; -- 查询鞋服分类下最贵的商品的全部信息 -- 多表查询 -- 1.查询鞋服分类中 最高的商品价格 SELECT MAX(p.`price`) FROM products p LEFT JOIN category c ON p.`category_id` = c.`cid` WHERE c.`cname` = '鞋服'; -- 2.进行子查询 将上面的查询结果作为条件 SELECT * FROM products p LEFT JOIN category c ON p.`category_id` = c.`cid` WHERE c.`cname` = '鞋服' AND p.`price` = ( SELECT MAX(p.`price`) FROM products p LEFT JOIN category c ON p.`category_id` = c.`cid` WHERE c.`cname` = '鞋服' ); -- 通过视图查询 SELECT * FROM products_category_view pc WHERE pc.`cname` = '鞋服' AND pc.`price` = ( -- 子查询 求出鞋服分类下的最高价格 SELECT MAX(pc.`price`) FROM products_category_view pc WHERE pc.`cname` = '鞋服' );
-
4.2.3 视图与表的区别
- 视图是建立在表的基础上,表存储数据库中的数据,而视图只是做一个数据的展示
- 通过视图不能改变表中数据(一般情况下视图中的数据都是表中的列,经过计算得到的结果,不允许更新)
- 删除视图,表不受影响,而删除表,视图不再起作用
4.3 存储过程(了解)
- MySQL 5.0 版本开始支持存储过程。
- 存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。存储过程是为了完成特定功能的 SQL 语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
- 简单理解:存储过程其实就是一堆 SQL 语句的合并。中间加入了一些逻辑控制。
4.3.1 优缺点
- 优点:
- 存储过程一旦调试完成后,就可以稳定运行(前提是,业务需求要相对稳定,没有变化)
- 存储过程减少业务系统与数据库的交互,降低耦合,数据库交互更加快捷(应用服务器,与数据库服务器不在同一个地区)
- 缺点:
- MySQL 的存储过程与 Oracle 的相比较弱,所以较少使用,并且互联网行业需求变化较快也是原因之一
- 尽量在简单的逻辑中使用,存储过程移植十分困难,数据库集群环境,保证各个库之间存储过程变更一致也十分困难。
- 阿里的代码规范里,明确禁止使用存储过程,存储过程维护起来比较麻烦;
4.3.2 使用
-
创建方式1
-
1 2 3 4 5 6 7 8DELIMITER $$ -- 声明语句结束符,可以自定义 一般使用$$CREATE PROCEDURE 过程名称() -- 声明存储过程 BEGIN -- 开始编写存储过程 -- 要执行的操作 END $$ -- 存储过程结束
-
-
创建方式2
-
1 2 3DELIMITER $$CREATE PROCEDURE 存储过程名称(IN 参数名 参数类型)BEGIN -- 要执行的操作 END $$
-
-
创建方式3
-
1 2 3 4 5 6DELIMITER $$ CREATE PROCEDURE 存储过程名称(IN 参数名 参数类型, OUT 变量名 数据类型) BEGIN -- 要执行的操作 SET @变量名=值 END $$
-
-
调用
-
1 2CALL 存储过程名称; CALL 存储过程名称(参数值);
-
|
|
4.4 触发器
触发器(trigger)是 MySQL 提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如对一个表进行操作(insert,delete, update)时就会激活它执行。——百度百科
简单理解:当我们执行一条 sql 语句的时候,这条 sql 语句的执行会自动去触发执行其他的 sql 语句。
4.4.1 触发器创建的四个要素
- 监视地点(table)
- 监视事件(insert/update/delete)
- 触发时间(before/after)
- 触发事件(insert/update/delete)
|
|
|
|
5 事务
事务是一个整体,由一条或者多条 SQL 语句组成,这些 SQL 语句要么都执行成功,要么都执行失败,只要有一条 SQL 出现异常,整个操作就会回滚,整个业务执行失败。
使用事务,可以避免某些异常情况的发生:
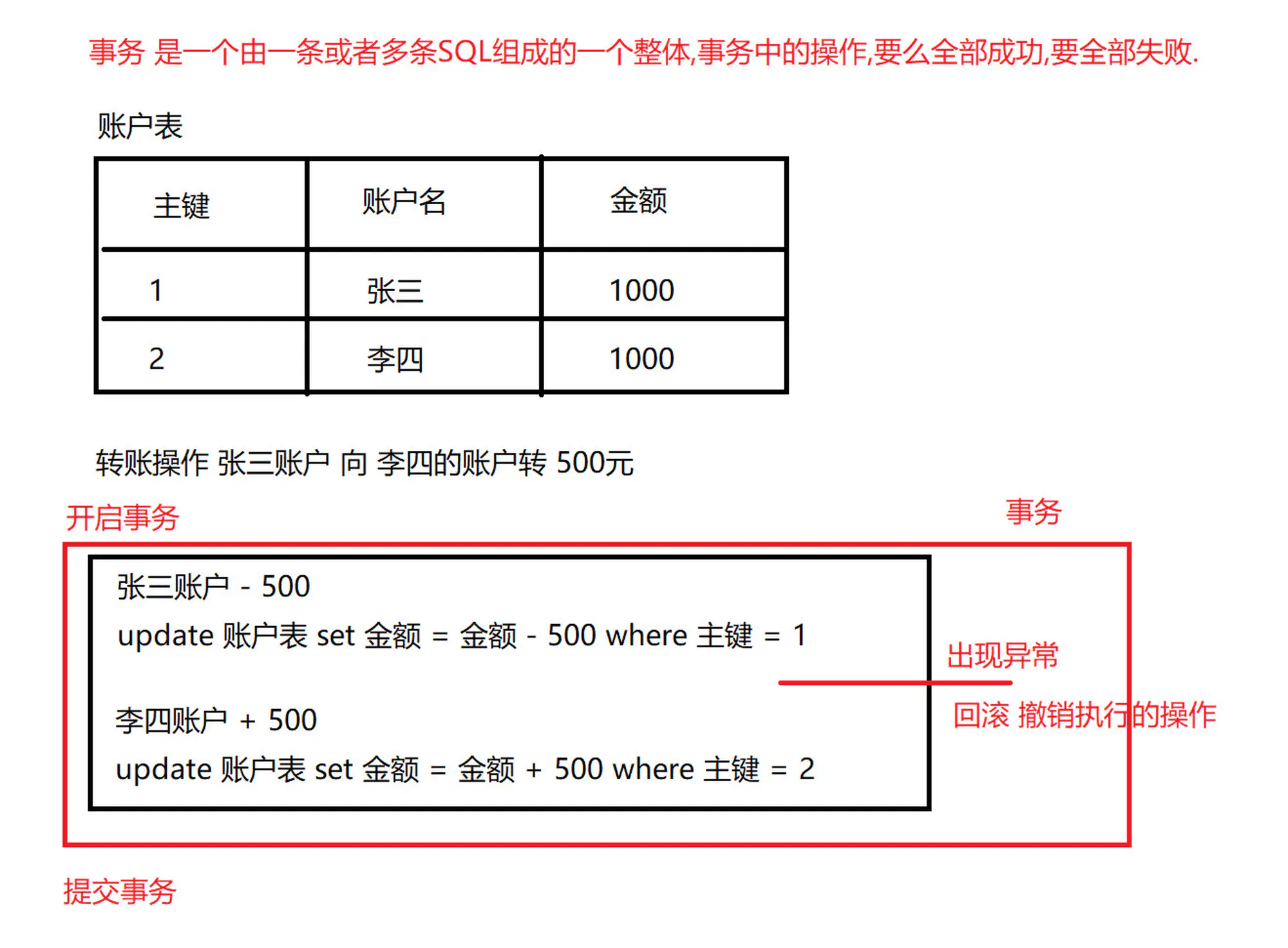
5.事务概述)
5.0.2 手动提交事务
-
START TRANSACTION;或者BEGIN;- 这个语句显式地标记一个事务的起始点。
-
COMMIT- 表示提交事务,即提交事务的所有操作,具体地说,就是将事务中所有对数据库的更新都写到磁盘上的物理数据库中,事务正常结束。
-
ROLLBACK- 表示撤销事务,即在事务运行的过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库的所有已完成的操作全部撤销,回滚到事务开始时的状态
-
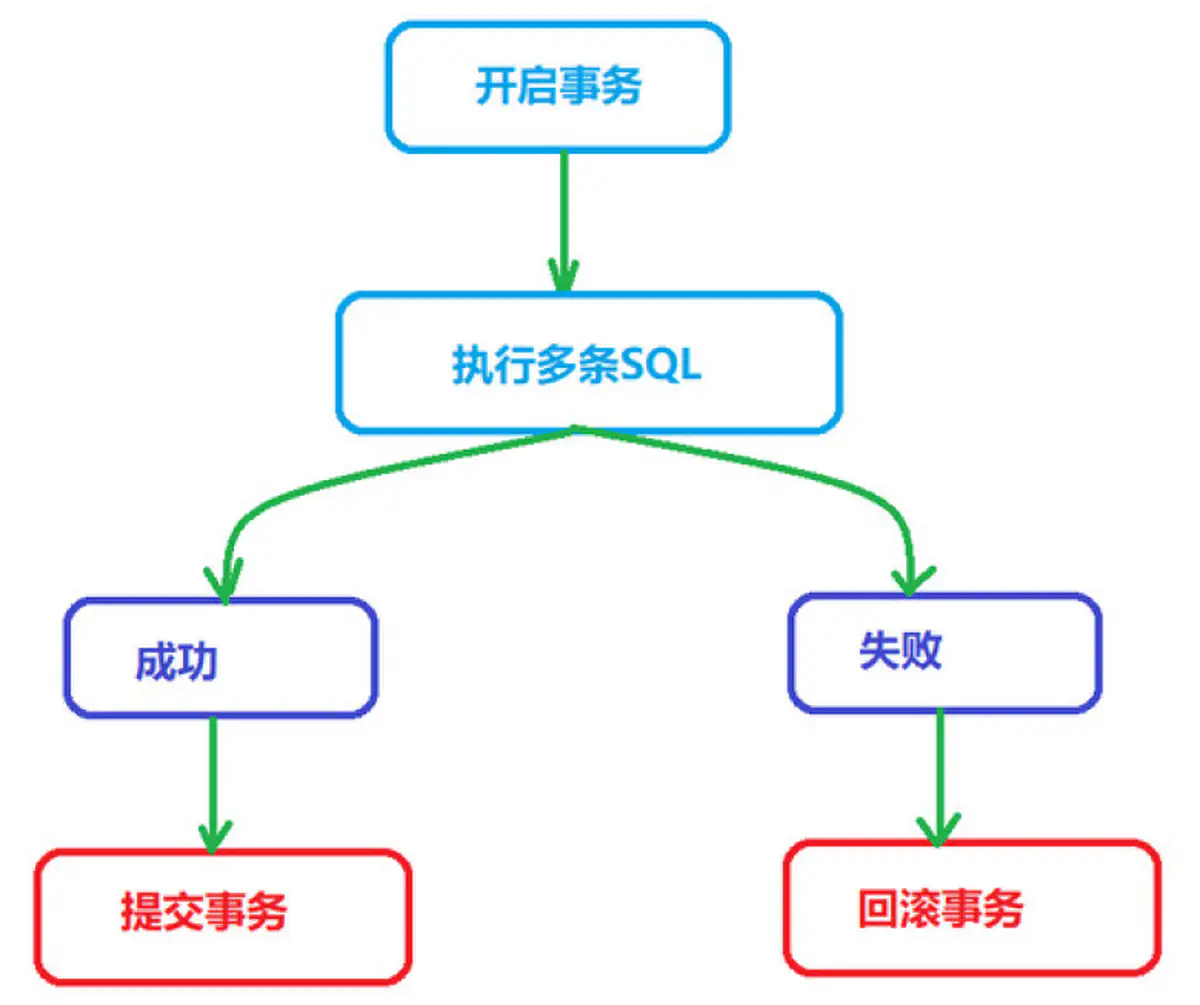
MySQL笔记_基础2( 6.事务流程) -
如果事务中 SQL 语句没有问题,commit 提交事务,会对数据库数据的数据进行改变。
-
如果事务中 SQL 语句有问题,rollback 回滚事务,会回退到开启事务时的状态。
|
|
5.0.3 自动提交事务
- 默认状态下,MySQL开启了自动提交事务
- 每一条 DML(增删改)语句作为一个单独的事务
|
|
5.0.4 MySQL 事务的四大特性
- 原子性
- 每个事务都是一个整体,不可以再拆分,事务中的所有 SQL
- 要么都执行成功,要么都执行失败
- 一致性
- 事务在执行之前,数据库的状态,与事务执行之后的状态要保持一致
- 隔离性
- 事务与事务之间不应该相互影响,执行时要保证隔离状态
- 持久性
- 一旦事务执行成功,对数据的修改是持久的
5.0.5 SQL 的隔离等级
- 各个事务之间是隔离,相互独立。
- 但是一个数据库可能拥有多个访问客户端,这些客户端都可以并发方式访问数据库,数据库的相同数据可能被多个事务同时访问,如果多个事务对数据库中的同一批数据进行并发访问的时候,就可能引发一些问题:
- 脏读(Dirty Read)
- 一个事务读到了另一个未提交事务修改过的数据
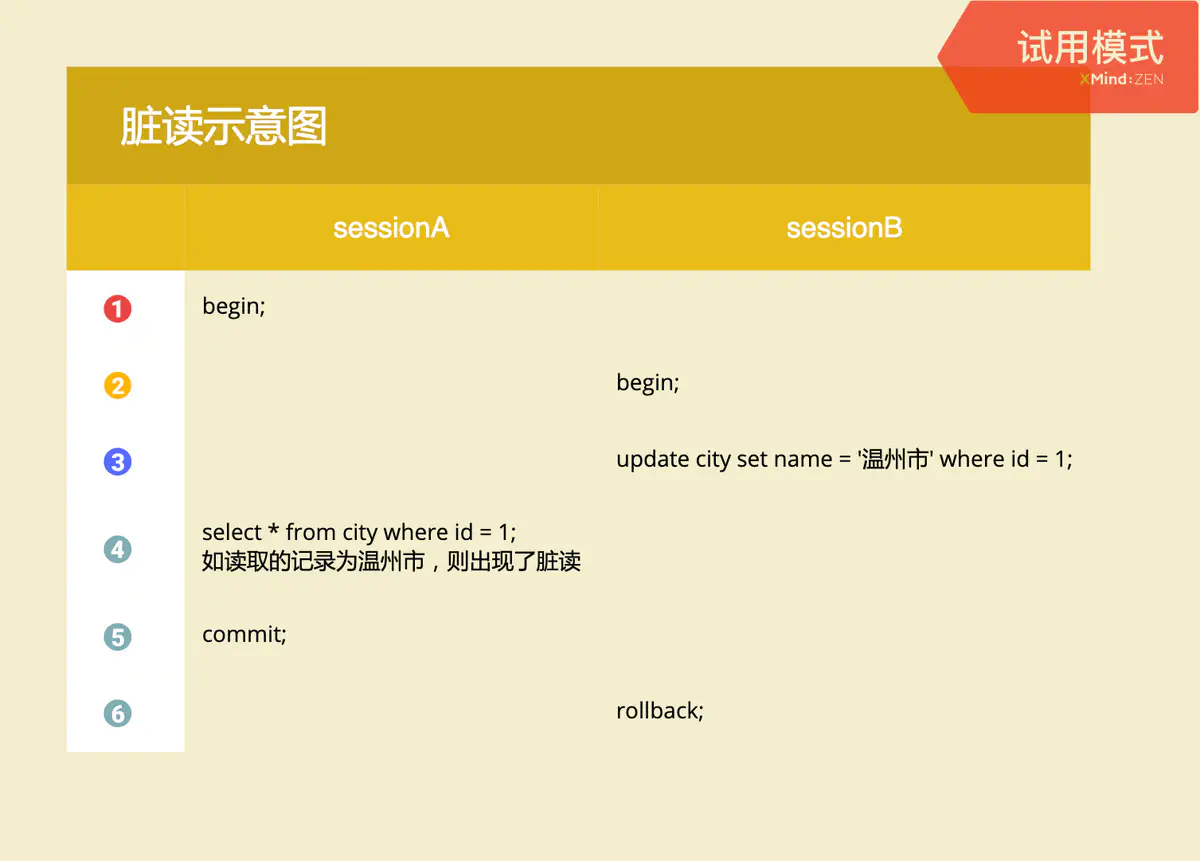
MySQL笔记_基础2( 7.脏读)
- 不可重复读(Non-Repeatable Read)
- 一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值

MySQL笔记_基础2( 8.不可重复读)
- 幻读(Phantom):
- 一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来。

MySQL笔记_基础2( 9.幻读)
- 脏读(Dirty Read)
- 可以通过设置不同的隔离级别来解决对应的问题
- read uncommitted,读未提交
- 可以防止:无
- read committed,读已提交( Oracle、MS_SQL_Server 的默认隔离级别)
- 可以防止:脏读
- repeatable read,可重复读( MySql 的默认隔离级别)
- 可以防止:脏读、不可重复读
- serializable,串行化(各事务排队执行,失去了并发的高效率优势)
- 可以防止:脏读、不可重复读、幻读
- 注意:隔离级别从小到大,安全性越来越高,但是效率越来越低,根据不同的情况选择对应的隔离级别
- read uncommitted,读未提交



5.0.5.1 查看及设置隔离级别的方法
|
|
5.0.5.2 脏读演示和解决
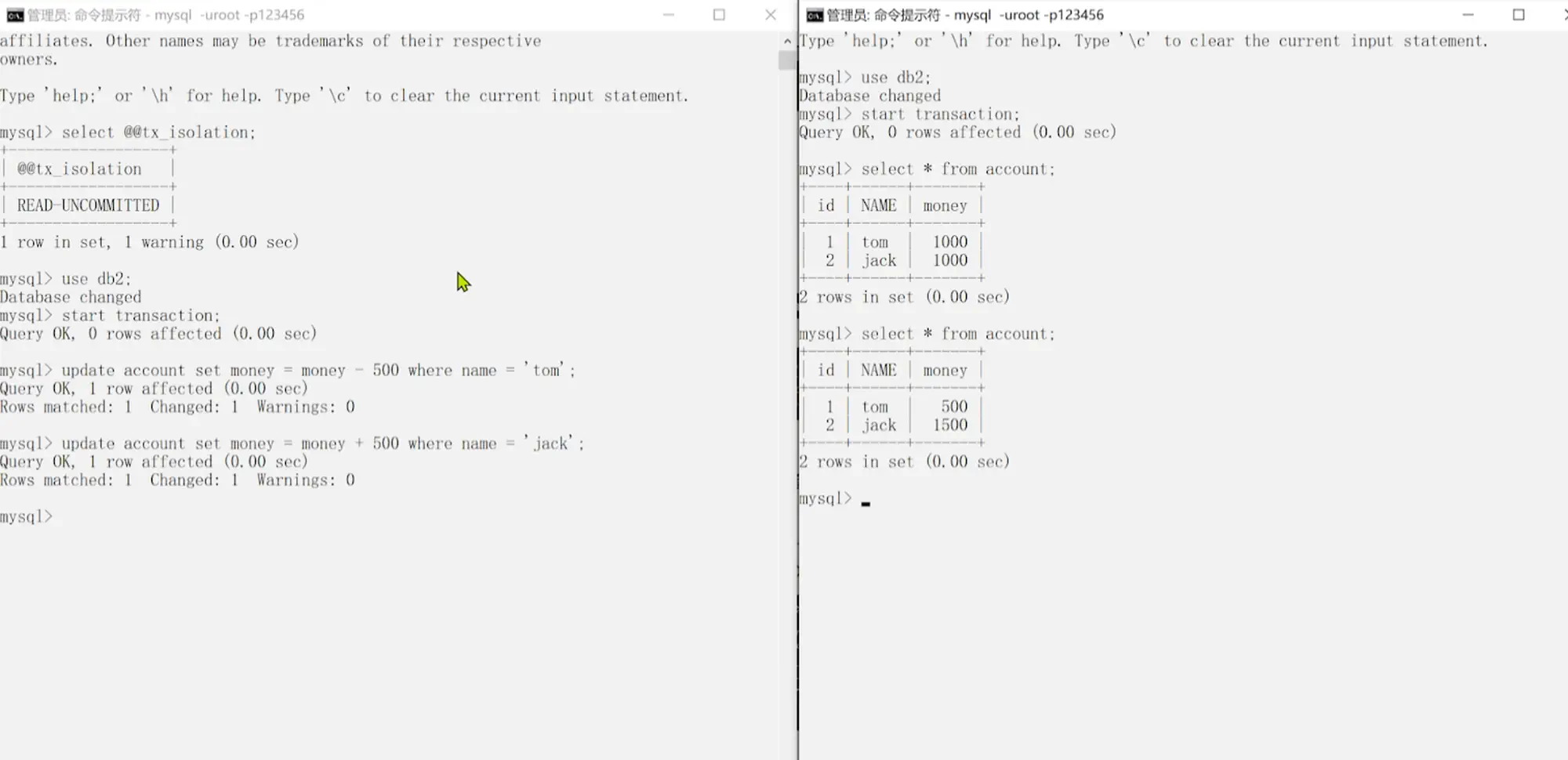
10.脏读演示)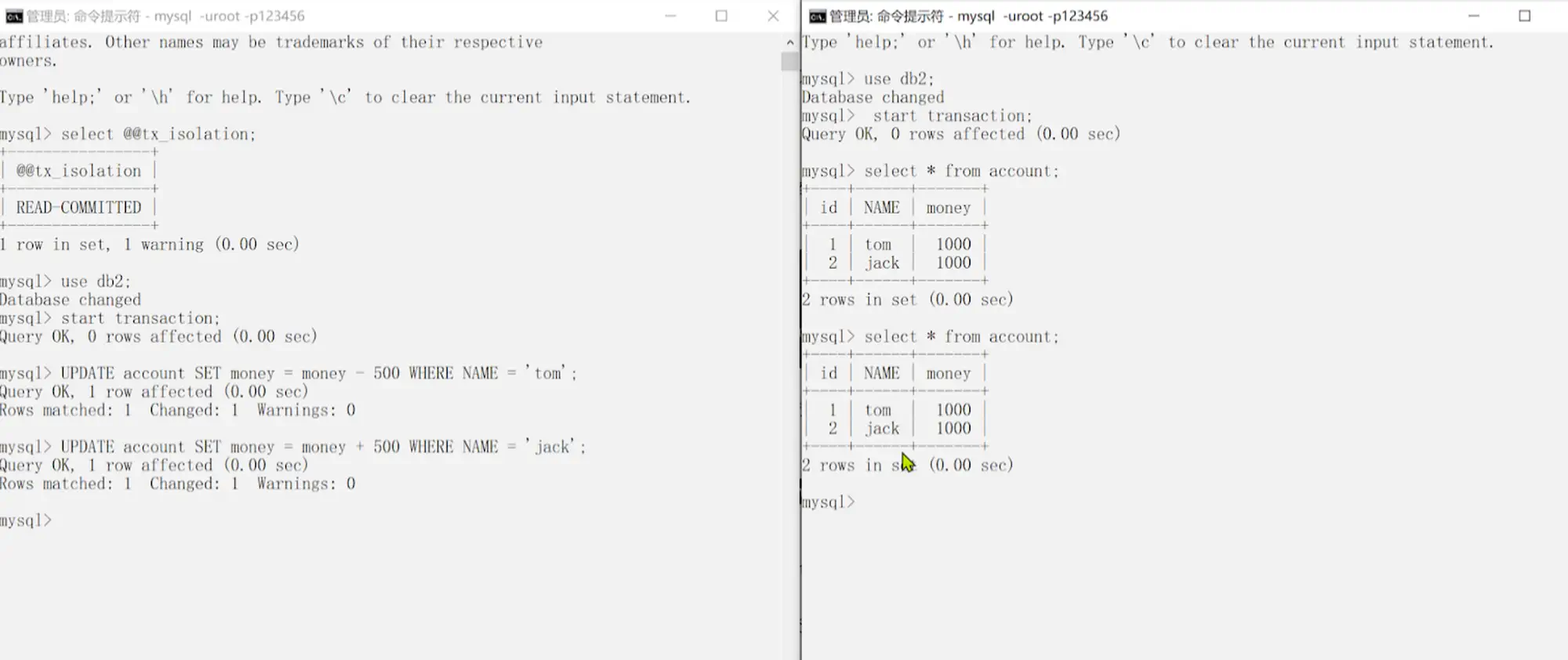
11.脏读解决)
5.0.5.3 不可重复读演示和解决
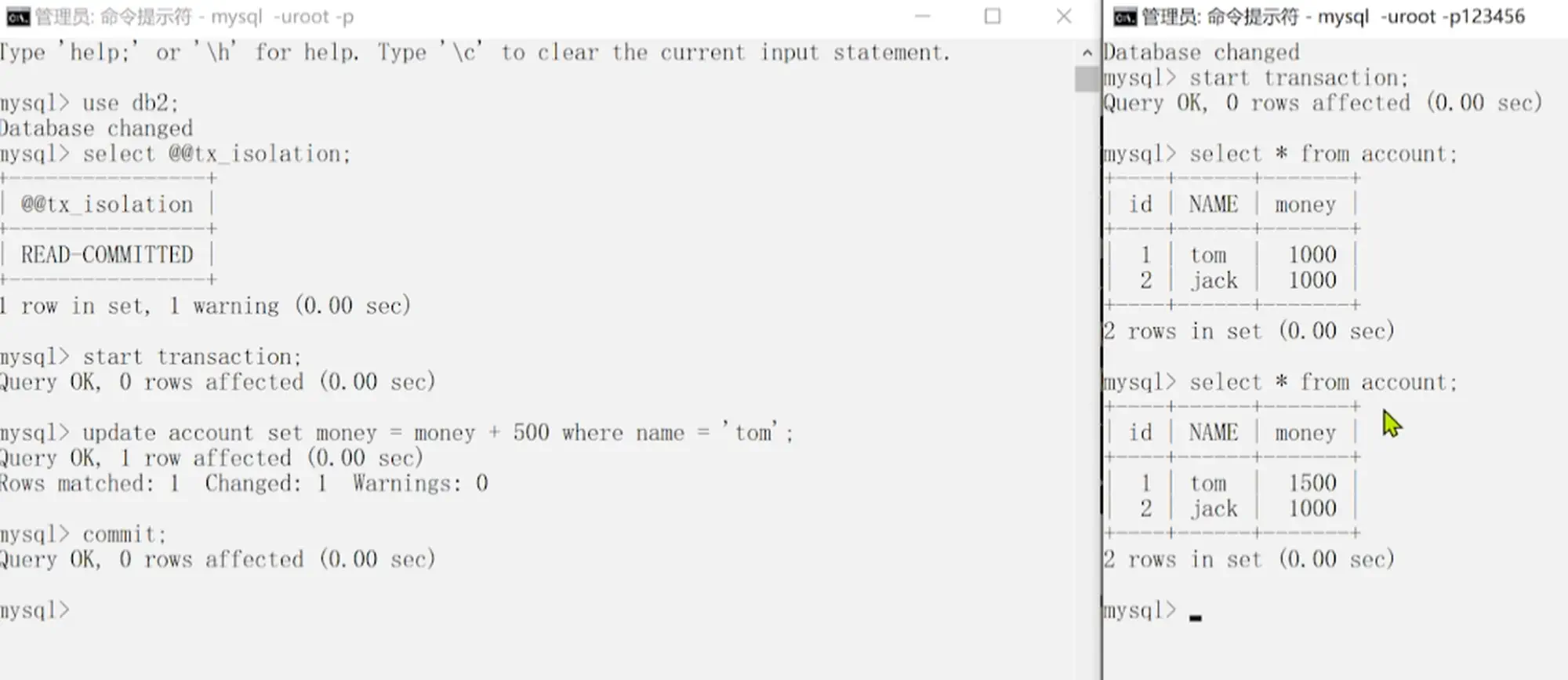
12.不可重复读演示)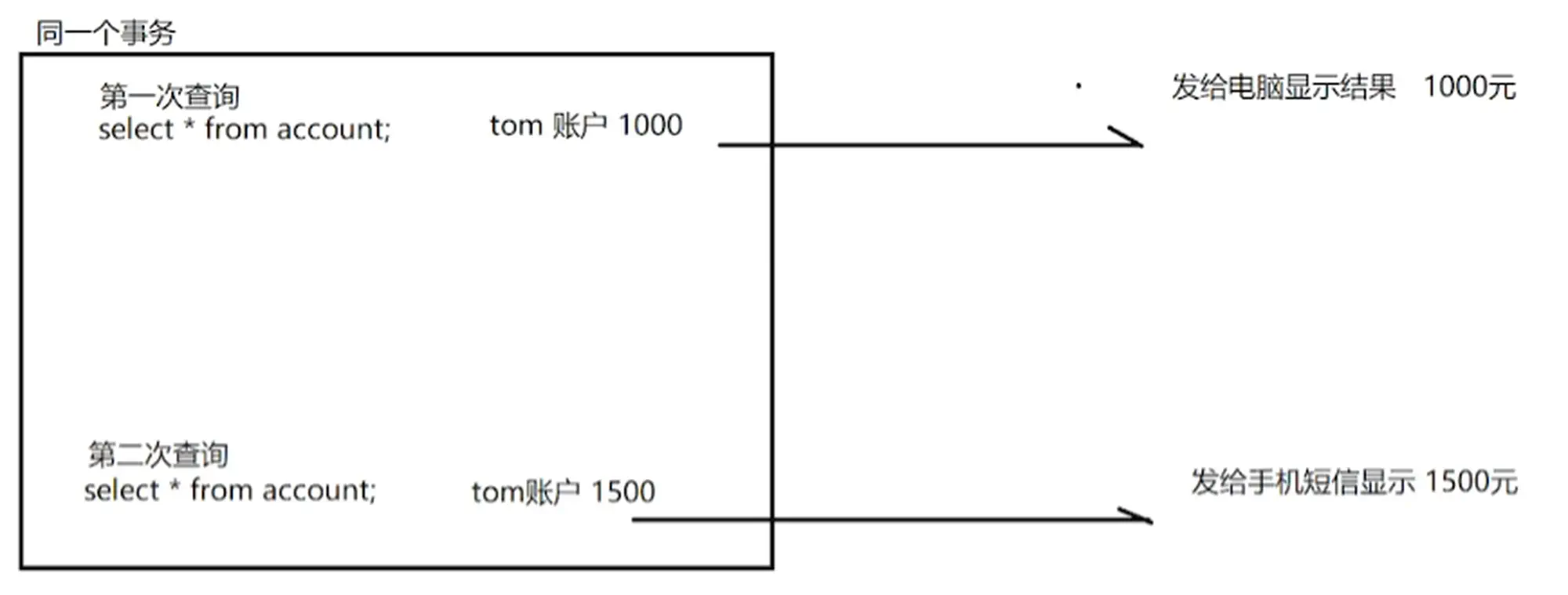
13.不可重复读问题场景)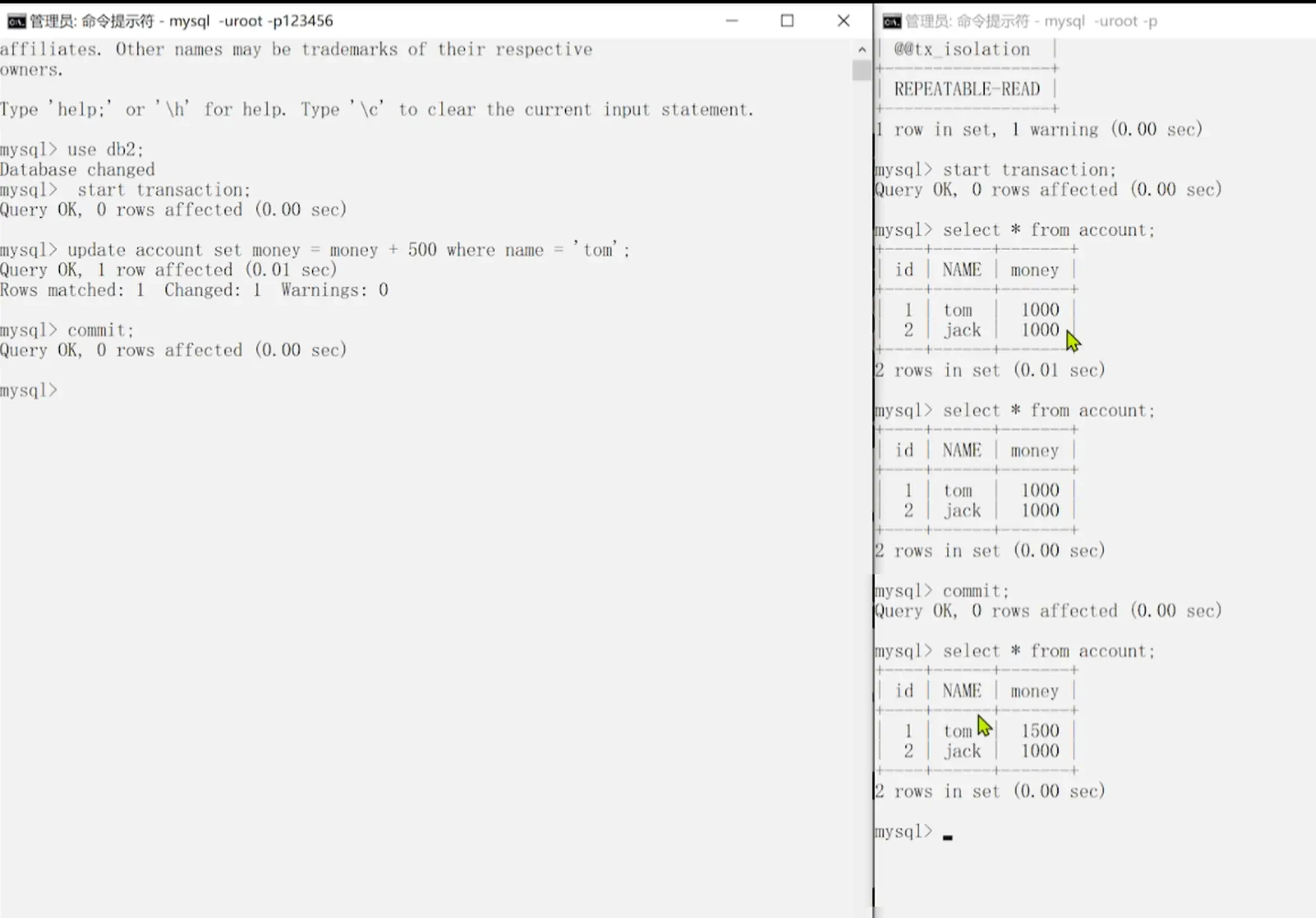
14.不可重复读解决)
5.0.5.4 幻读演示和解决
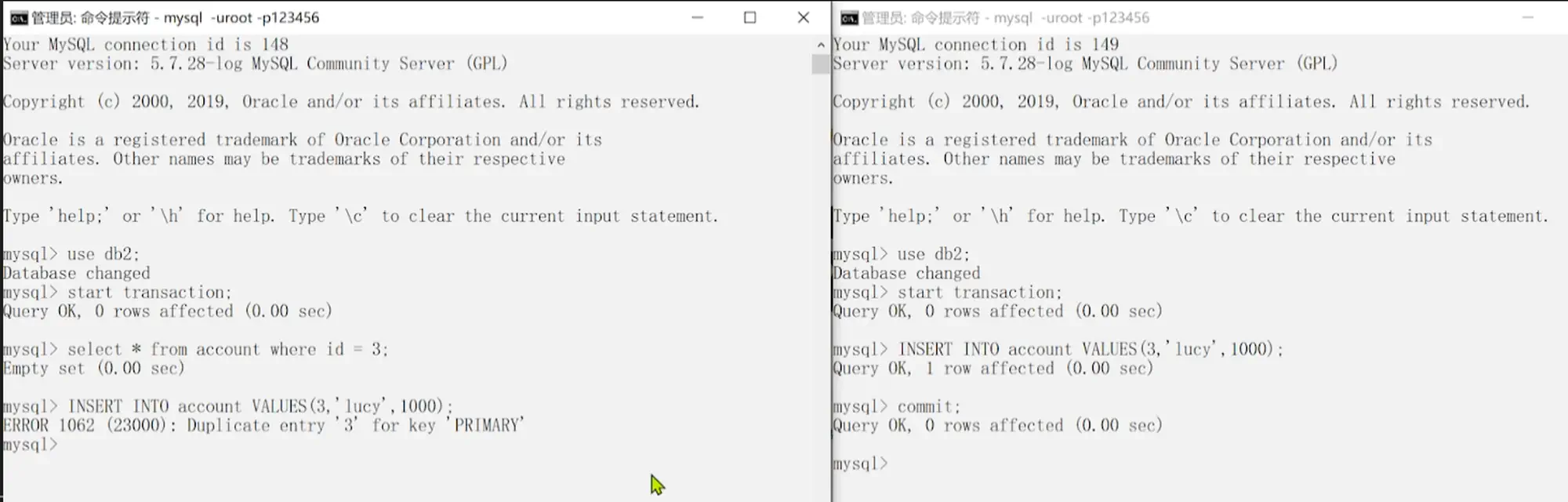
15.幻读演示)教学视频中能直观地看到,一个线程会等待另一个线程 commit; 之后,再执行命令