
用于学习的大数据集群环境搭建(上)
用于学习的大数据集群环境搭建(上)
最近学习用的集群连续出现问题,用的时间有点长了,东西太多,于是推倒重建,顺便复习温故
1 准备
1.1 虚拟机设置
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| hostname | node1.lvm-domain | node2.lvm-domain | node3.lvm-domain |
| ip | 172.31.31.51 | 172.31.31.52 | 172.31.31.53 |
| CPU内核数 | 4 | 2 | 2 |
| 内存 | 4 | 2 | 2 |
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
1.2 系统安装
CentOS-7-2009 最小化安装
使用 “DHCP-保留地址” 的方式固定 IP 地址
关机,快照 000
1.3 安装常用工具,update
|
|
关机,快照 001
1.4 关防火墙、SELinux
|
|
|
|
1.5 SSH 免密登录
-
修改 host 文件
-
1 2 3 4 5echo 172.31.31.51 node1 >> /etc/hosts echo 172.31.31.52 node2 >> /etc/hosts echo 172.31.31.53 node3 >> /etc/hosts less /etc/hosts
-
-
三台主机,分别生成密钥
-
1 2ssh-keygen -t rsa ls -Alph ~/.ssh
-
-
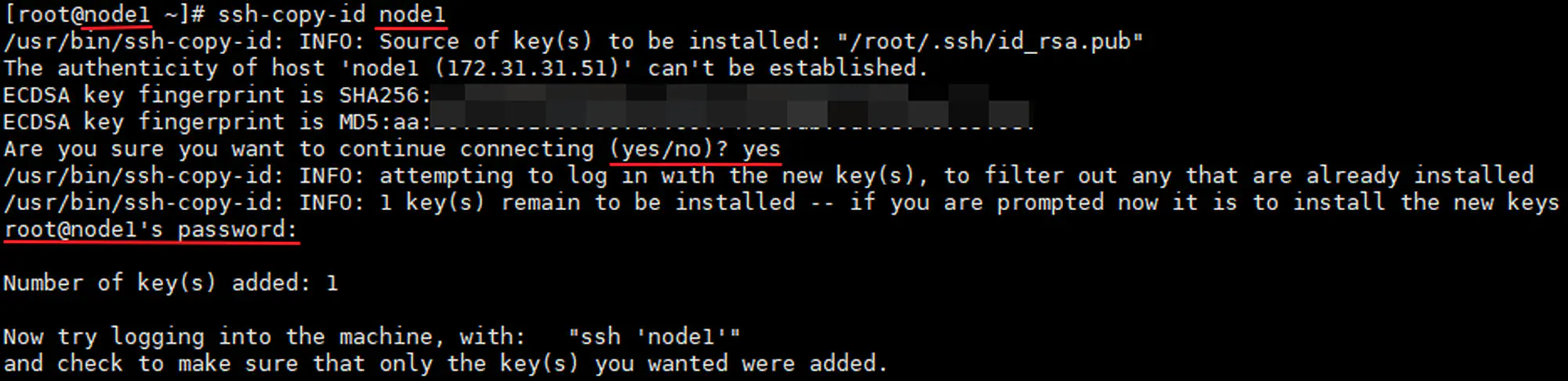
三台主机,分别将各自的公钥,拷贝给 node1:
-
1 2 3 4 5 6ssh-copy-id node1 # 每台主机(包括 node1 自己)第一次以 ssh 协议连接到 node1 需要输入 yes 进行密钥确认,并输入 node1 的 root 密码 # 验证:在 node1 上检查 cat ~/.ssh/authorized_keys cat ~/.ssh/known_hosts -
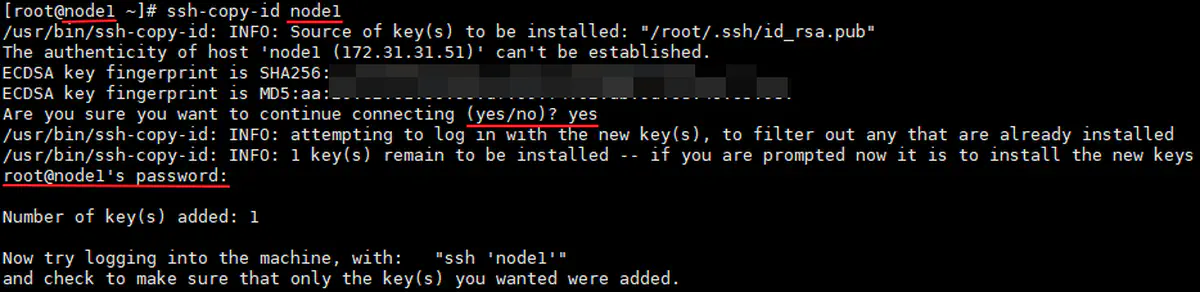
001
-
-
将 authorized_keys ,分发给另外两台主机
-
1 2 3 4cd ~/.ssh scp authorized_keys node2:$PWD scp authorized_keys node3:$PWD # node1 第一次以 ssh 协议连接到另外两台节点,同样需要输入 yes 进行密钥确认,并输入目标节点的 root 密码 -

002
-
-
验证:三台主机之间,再通过ssh互相登录,不再需要输入密码
-
1 2 3ssh node1 "hostname;" ssh node2 "hostname;" ssh node3 "hostname;" -
此时:
- 由于 node1 上已经有全部主机的密钥,并且在步骤 3 确认过本机的密钥,在步骤 4 确认过另外两台主机的密钥,所以全部能够直接登录
- 此时另外两台主机也有了全部主机的密钥,并且在步骤 3 确认过 node1 的密钥,所以无需确认直接登录;但对其他主机,还是第一次连接,需要进行确认(但因为有了密钥,不需要输入密码)
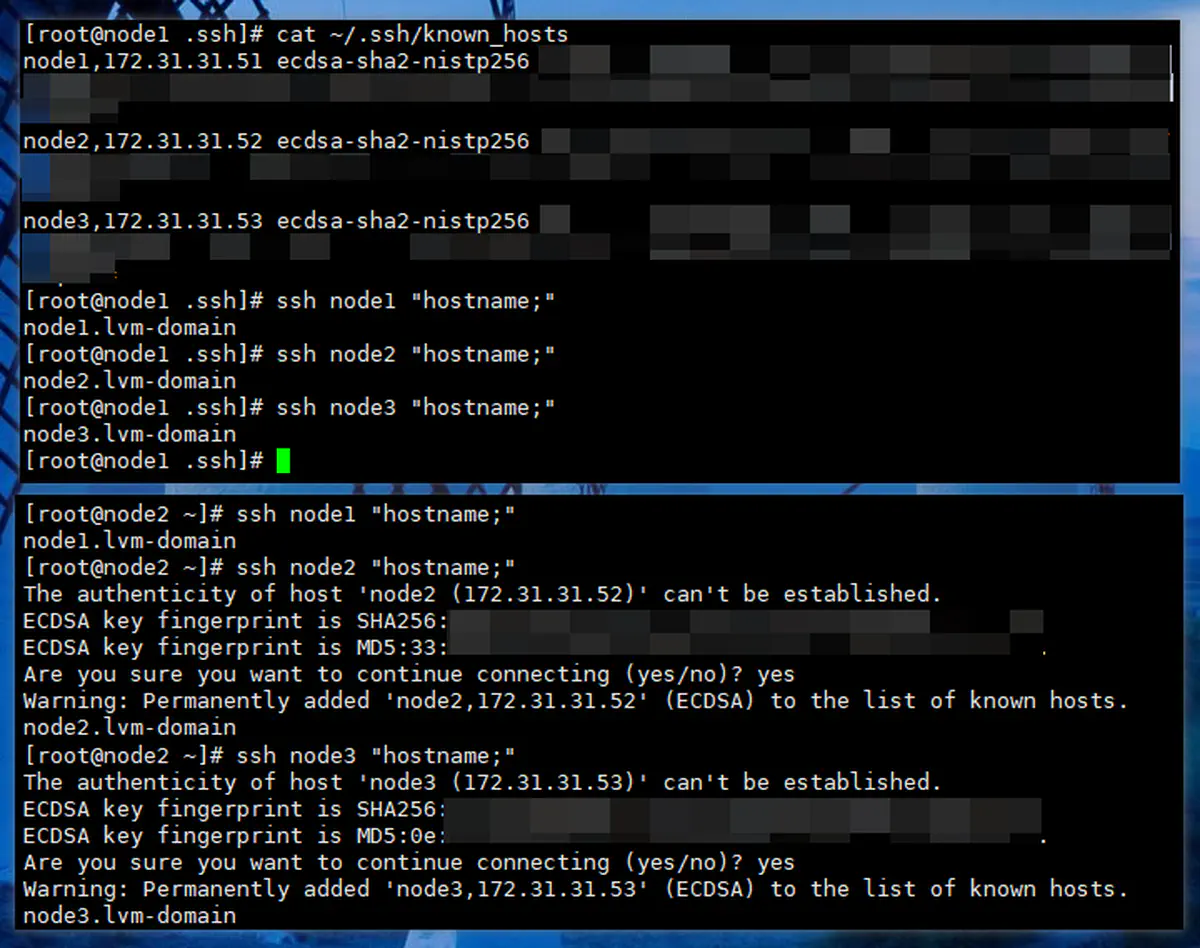
003
-

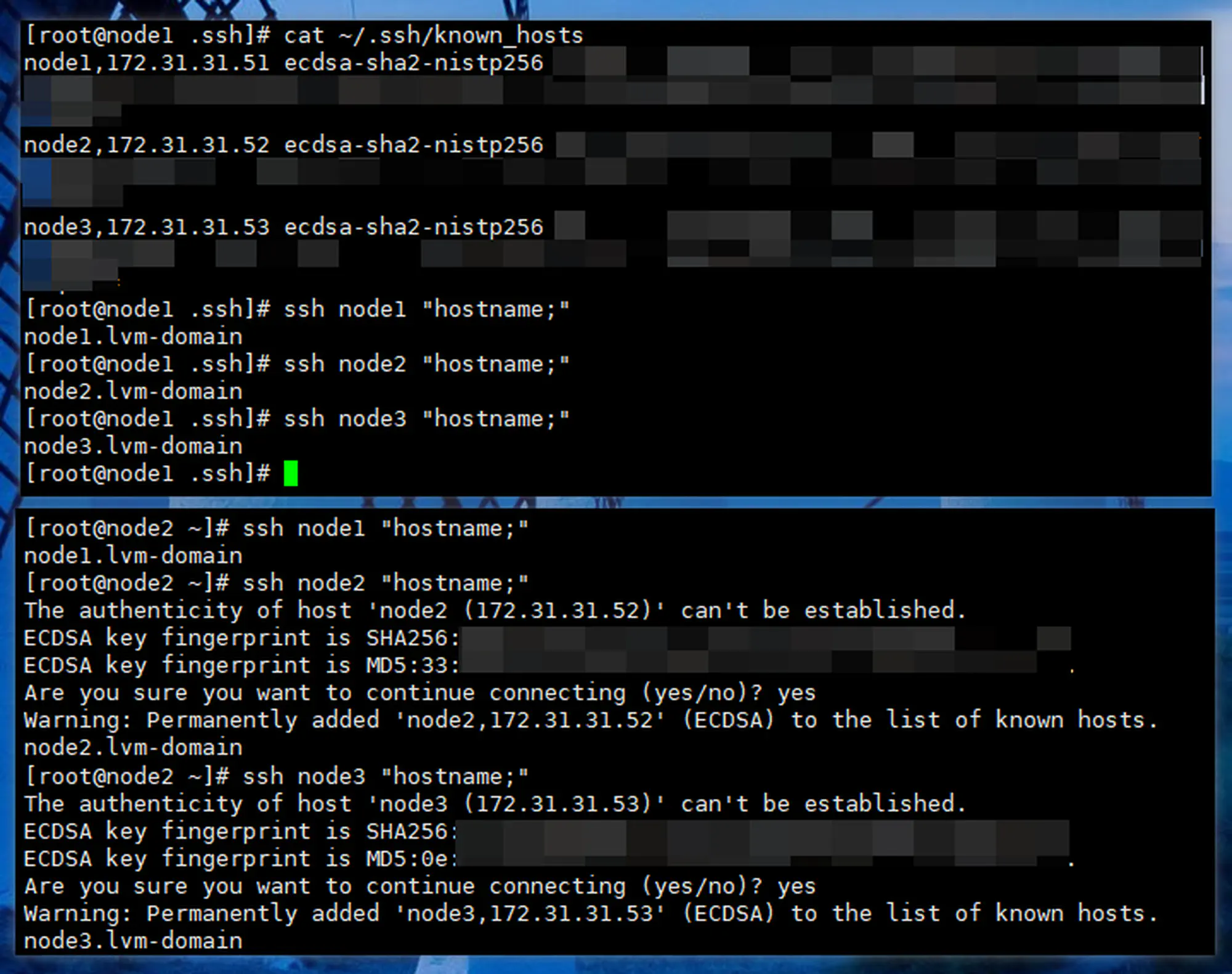
关机,快照 002
1.6 对时
暂时没做这步。一般情况下虚拟机直接从(同一个)硬件时钟获取时间,应该不存在时间不同步的问题
1.7 准备目录和脚本
|
|
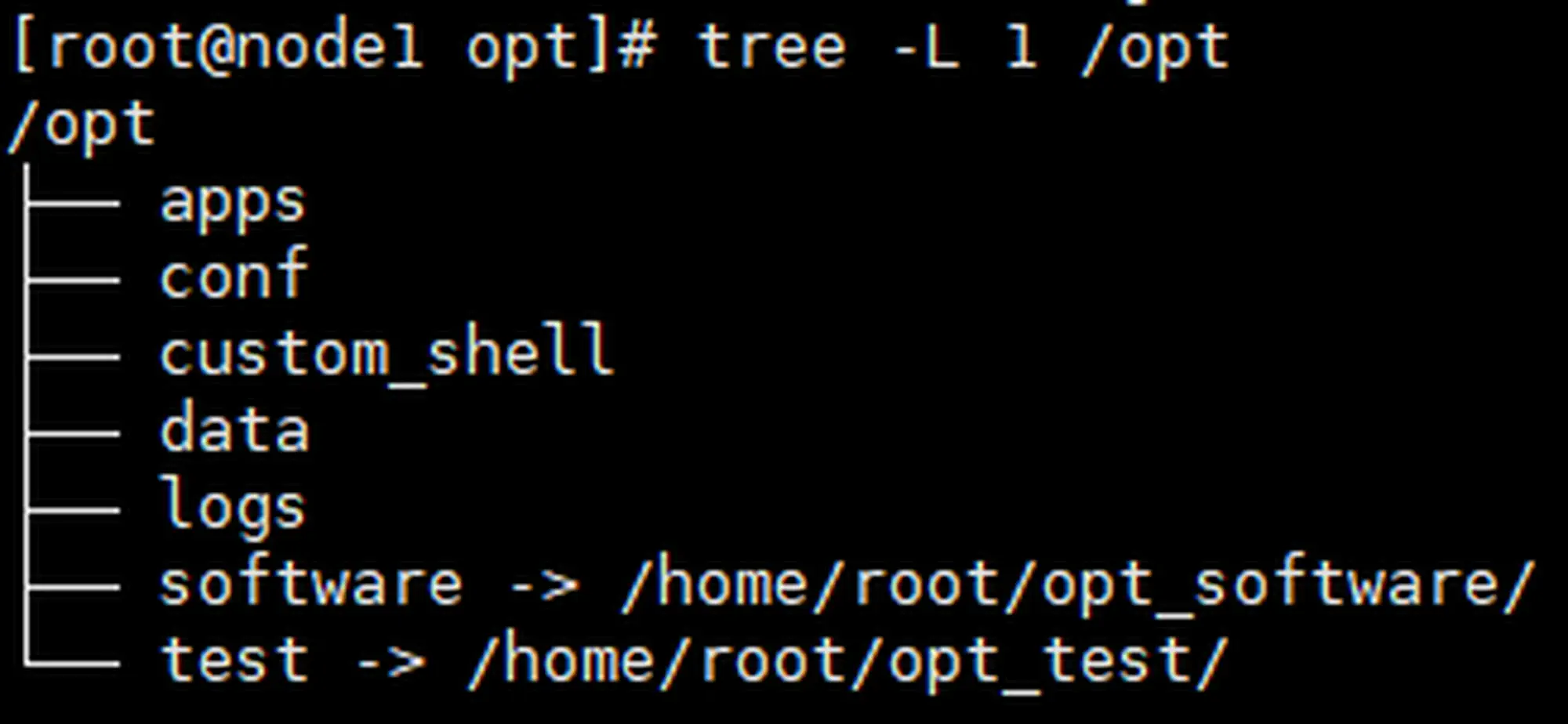
给脚本目录设置一下环境变量 $CS ,和执行权限
|
|
脚本见最后的附录
2 集群规划
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| hostname | node1.lvm-domain | node2.lvm-domain | node3.lvm-domain |
| ip | 172.31.31.51 | 172.31.31.52 | 172.31.31.53 |
| CPU内核数 | 4 | 2 | 2 |
| 内存 | 4 | 2 | 2 |
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
| ———- | ———- | ———- | ———- |
| »> ZooKeeper : | ✔ | ✔ | ✔ |
| ———- | ———- | ———- | ———- |
| »> Hadoop : | |||
| JournalNode | ✔ | ✔ | ✔ |
| NameNode | ✘ | ✔ | ✔ |
| SecondaryNameNode | ✘ | ✘ | ✘ |
| DataNode | ✔ | ✔ | ✔ |
| ResourceManager | ✘ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ |
| JobHistoryServer | ✔ | ✘ | ✘ |
| ———- | ———- | ———- | ———- |
| »> HIVE(远程部署模式): | |||
| MetadataDB(MySQL) | ✔ | ✘ | ✘ |
| Hive Client(非常驻) | ✔ | ✔ | ✔ |
| Metastore | ✔ | ✘ | ✘ |
| HiveServer2(用到再装) | (✔) | ✘ | ✘ |
| Beeline Client(非常驻,可连H2) | (✔) | (✔) | (✔) |
| HCatalog(非常驻,不常用) | (✔) | (✔) | (✔) |
| ———- | ———- | ———- | ———- |
| »> Tez(无后台服务): | ✔ | ✔ | ✔ |
| ———- | ———- | ———- | ———- |
| »> Flume(无后台服务): | ✔ | ✔ | ✔ |
| ———- | ———- | ———- | ———- |
| »> DataX(无后台服务): | ✔ | ✔ | ✔ |
3 安装 JDK
-
下载(略)
-
解压
-
1 2 3 4 5 6 7cd /opt/software/ ls tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz ls mv java-se-8u41-ri/ /opt/apps/open_jdk8u41 ls ls /opt/apps/
-
-
配置环境变量,并同步到其他主机
-
1 2 3 4 5 6 7 8 9 10# 配置环境变量 echo " " >> /etc/profile echo "# OpenJDK" >> /etc/profile echo "export JAVA_HOME=/opt/apps/open_jdk8u41" >> /etc/profile echo "export CLASSPATH=.:\${JAVA_HOME}/jre/lib/rt.jar:\${JAVA_HOME}/lib/dt.jar:\${JAVA_HOME}/lib/tools.jar" >> /etc/profile echo "export PATH=\$PATH:\${JAVA_HOME}/bin" >> /etc/profile # 同步到其他主机 $CS/rsync.sh /opt/apps/open_jdk8u41 $CS/rsync.sh /etc/profile
-
-
在每台主机上刷新环境变量并验证
-
1 2 3source /etc/profile echo $JAVA_HOME java -version
-
4 安装 ZooKeeper
4.1 规划
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
| »>ZooKeeper: | ✔ | ✔ | ✔ |
4.2 安装
-
下载(略)
-
解压
-
1 2 3 4 5 6 7cd /opt/software/ ls tar -zxvf zookeeper-3.4.14.tar.gz ls mv zookeeper-3.4.14/ /opt/apps ls ls /opt/apps/
-
-
配置
-
1 2 3 4 5 6 7 8 9 10 11# 创建 data 目录 mkdir -p /opt/data/zk # 创建 log 目录 mkdir -p /opt/logs/zk # 修改配置文件 cd /opt/apps/zookeeper-3.4.14/conf ls cp zoo_sample.cfg zoo.cfg nano /opt/apps/zookeeper-3.4.14/conf/zoo.cfg # 编辑配置文件(内容如下) -
1 2 3 4 5 6 7 8 9 10 11 12# 指定 data 与 log 目录 dataDir=/opt/data/zk dataLogDir=/opt/logs/zk # 配置集群节点 # server.服务器 ID = 服务器(主机名或 IP ):通信端口:选举端口 server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888 # 自动清理事务日志和快照文件的间隔时间(小时) autopurge.purgeInterval=24
-
-
添加环境变量
-
1 2 3 4 5# 配置环境变量 echo " " >> /etc/profile echo "# ZooKeeper" >> /etc/profile echo "export ZK_HOME=/opt/apps/zookeeper-3.4.14" >> /etc/profile echo "export PATH=\$PATH:\$ZK_HOME/bin" >> /etc/profile
-
-
同步
-
1 2 3 4 5 6$CS/rsync.sh /opt/apps/zookeeper-3.4.14 $CS/rsync.sh /etc/profile # 各主机上刷新环境变量,并验证 source /etc/profile echo $ZK_HOME
-
-
给各节点设置 ID
-
1 2 3ssh node1 "echo 1 > /opt/data/zk/myid;" ssh node2 "echo 2 > /opt/data/zk/myid;" ssh node3 "echo 3 > /opt/data/zk/myid;"
-
4.3 启动和验证
-
启动
-
1 2 3$CS/zk.sh start # stop 参数,关闭 # status 参数,查看状态
-
-
使用
zkCli.sh客户端进行,各节点都能打开zkCli.sh客户端(但平常在 node1 上操作)-
1 2 3 4 5 6zkCli.sh # 连接到本地服务器的默认端口(2181) # zkCli.sh -server {主机名|IP}[:port] zkCli.sh -server node2:2181 zkCli.sh -server node3:2181 -
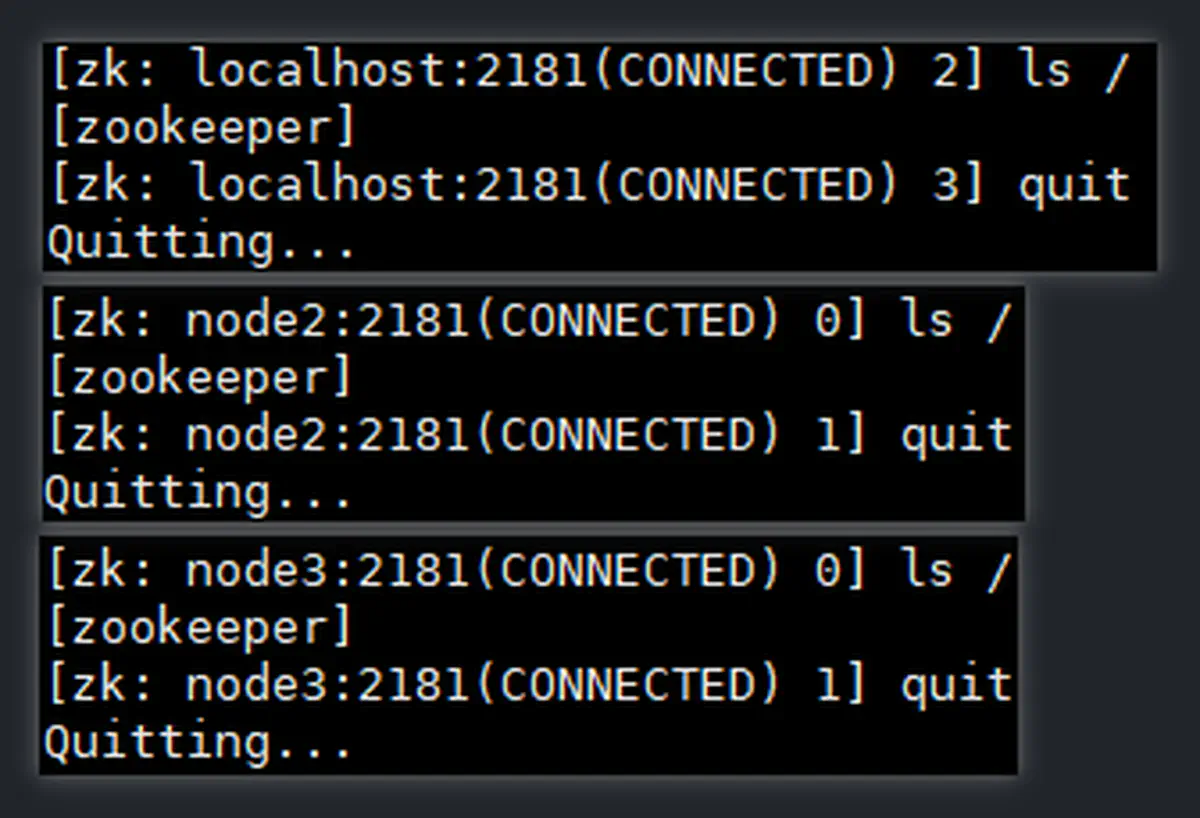
005
-
-
读写测试:
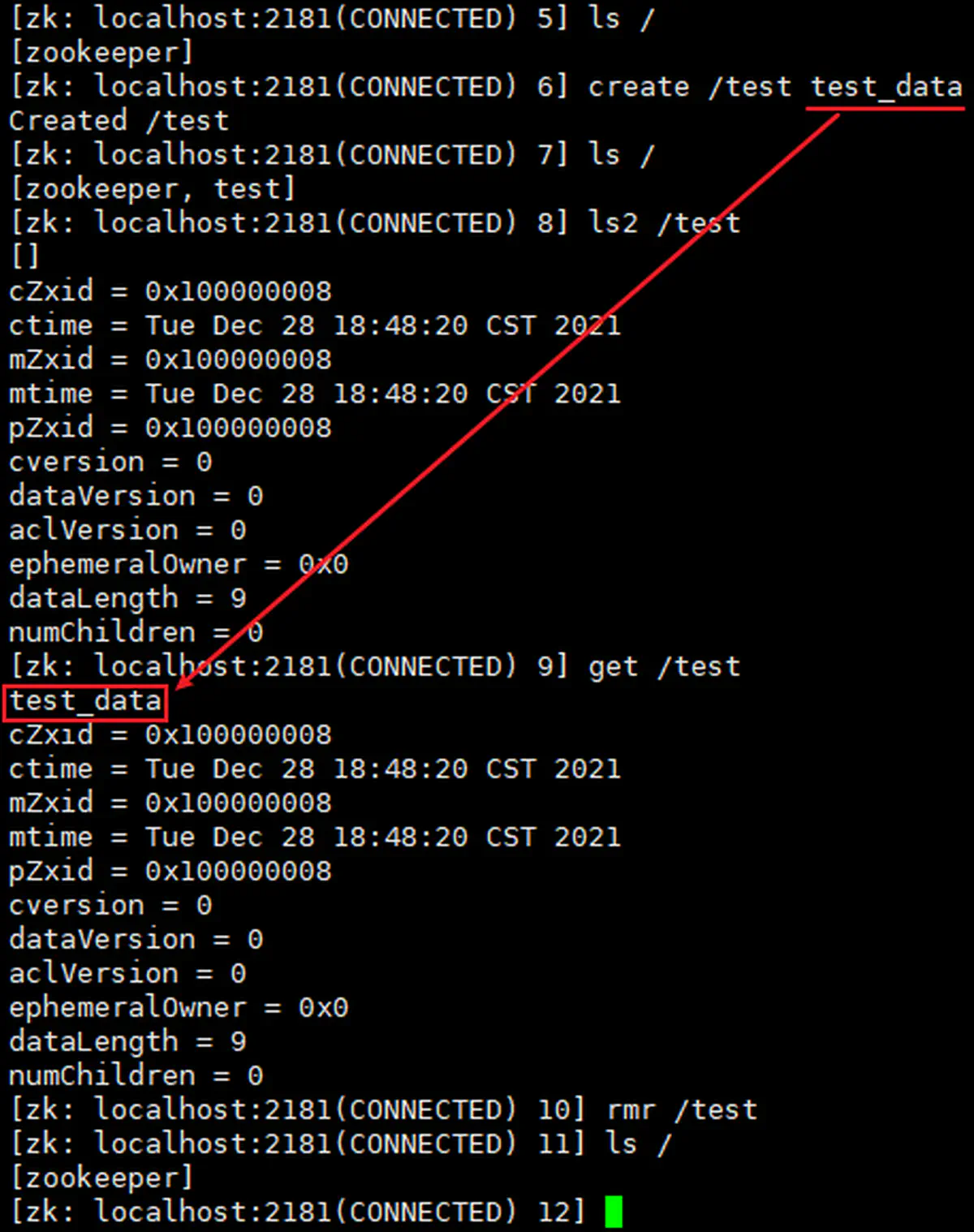
006
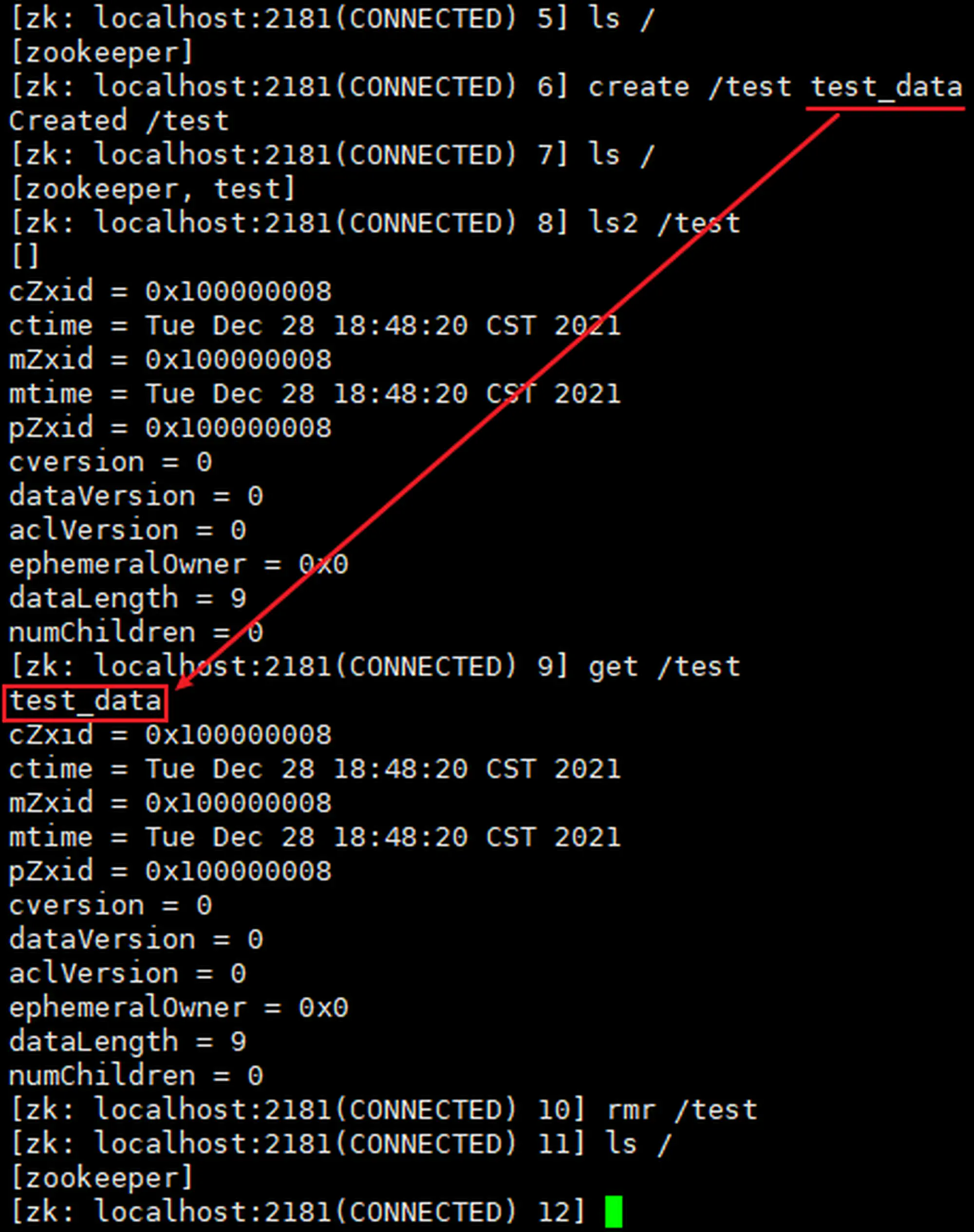
关机,快照 003
5 安装 Hadoop
5.1 规划
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
| »>Hadoop: | |||
| JournalNode | ✔ | ✔ | ✔ |
| NameNode | ✘ | ✔ | ✔ |
| SecondaryNameNode | ✘ | ✘ | ✘ |
| DataNode | ✔ | ✔ | ✔ |
| ResourceManager | ✘ | ✔ | ✔ |
| NodeManager | ✔ | ✔ | ✔ |
| JobHistoryServer | ✔ | ✘ | ✘ |
5.2 安装
5.2.1 下载解压
|
|
5.2.2 HDFS 与 Core 配置
-
Hadoop 配置文件目录
-
1 2cd /opt/apps/hadoop-2.10.1/etc/hadoop/ ls
-
-
修改
hadoop-env.sh-
1 2nano hadoop-env.sh # 指定 JDK 目录 -
1 2#export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/opt/apps/open_jdk8u41
-
-
修改
core-site.xml-
1 2mkdir -p /opt/data/hadoop nano core-site.xml -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26<configuration> <!-- 指定 Hadoop 运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop</value> </property> <!-- 非 HA 模式指定 HDFS 中 NameNode 的地址 --> <!-- <property> --> <!-- <name>fs.defaultFS</name> --> <!-- <value>hdfs://node2:9000</value> --> <!-- </property> --> <!-- 以下为 HA 集群配置 --> <property> <name>fs.defaultFS</name> <value>hdfs://hdfscluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> </configuration>
-
-
修改
hdfs-site.xml-
1 2mkdir -p /opt/data/journalnode nano hdfs-site.xml -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84<configuration> <!-- 指定 secondary namenode 主机配置( HA 模式不需要) --> <!-- <property> --> <!-- <name>dfs.namenode.secondary.http-address</name> --> <!-- <value>node3:50090</value> --> <!-- </property> --> <!-- 副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 关闭 hdfs 文件权限验证(Web、HUE...) --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <!-- 以下为 HA 集群配置 --> <property> <name>dfs.nameservices</name> <value>hdfscluster</value> </property> <property> <name>dfs.ha.namenodes.hdfscluster</name> <value>nn2,nn3</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.nn2</name> <value>node2:9000</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.nn3</name> <value>node3:9000</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.nn2</name> <value>node2:50070</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.nn3</name> <value>node3:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/lagou</value> </property> <property> <name>dfs.client.failover.proxy.provider.hdfscluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <!-- <value>sshfence</value> --> <!-- <value>sshfence(root)</value> --> <!-- <value>shell(/bin/true)</value> --> <value> sshfence shell(/bin/true) </value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/data/journalnode</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
-
-
创建、编写
slaves文件(不要有空行,行尾不要有空格)-
1 2 3 4 5 6 7 8 9pwd touch slaves echo node1 > slaves echo node2 >> slaves echo node3 >> slaves less slaves wc slaves
-
5.2.3 MapReduce 配置
-
修改
mapred-env.sh-
1 2nano mapred-env.sh # 指定 JDK 目录 -
1export JAVA_HOME=/opt/apps/open_jdk8u41
-
-
指定 MapReduce 计算框架使用 Yarn 进行资源调度
-
1 2cp mapred-site.xml.template mapred-site.xml nano mapred-site.xml -
1 2 3 4 5 6 7 8 9<configuration> <!-- 指定 MR 运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
5.2.4 Yarn 配置
-
修改
yarn-env.sh-
1nano yarn-env.sh -
1 2# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ export JAVA_HOME=/opt/apps/open_jdk8u41
-
-
修改
yarn-site.xml-
1nano yarn-site.xml -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78<configuration> <!-- 非 HA 模式,指定 YARN 的 ResourceManager 的地址 --> <!-- <property> --> <!-- <name>yarn.resourcemanager.hostname</name> --> <!-- <value>node3</value> --> <!-- </property> --> <!-- Reducer 获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置为 28 天(单位:秒) --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>2419200</value> </property> <!-- 日志服务器 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 以下为 HA 集群配置 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm2,rm3</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm3</name> <value>node3</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node2:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm3</name> <value>node3:8088</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- 将 RM 的状态信息储存在 ZK 集群 --> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration>
-
5.2.5 设置环境变量
|
|
5.2.6 同步和验证环境变量
|
|
5.3 启动和验证
5.3.1 (初次)启动 HDFS
|
|
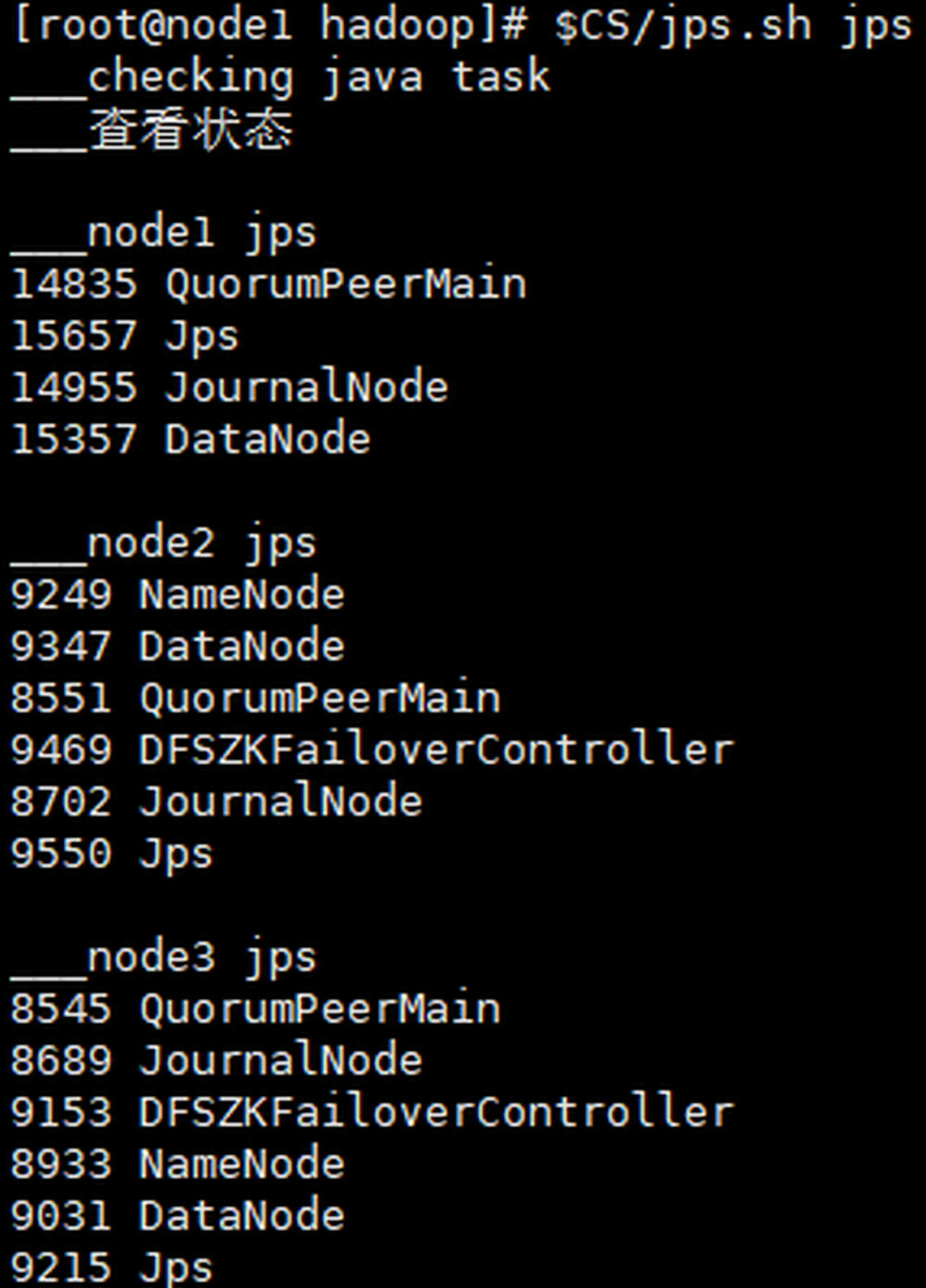
5.3.2 验证 HDFS
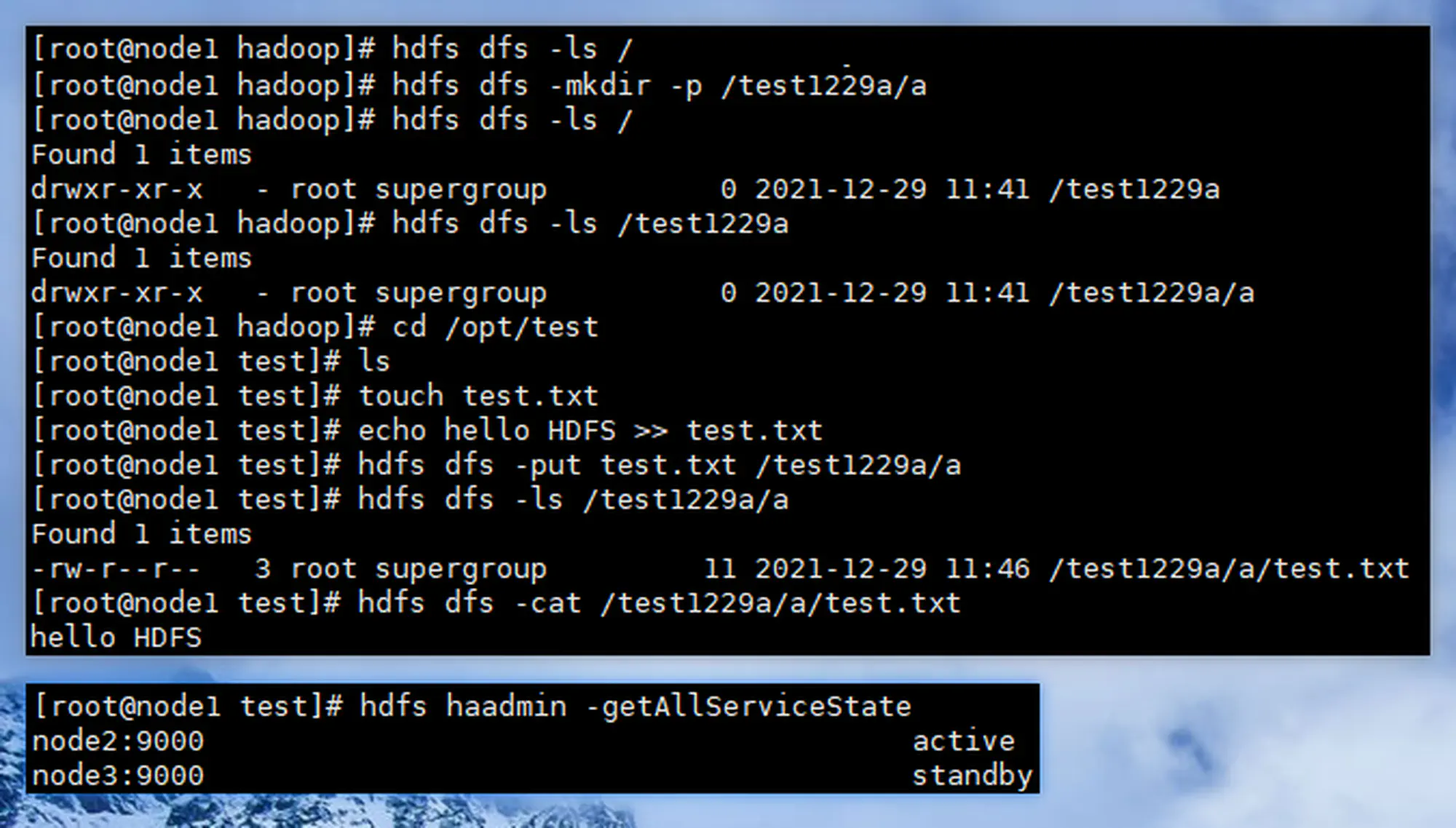
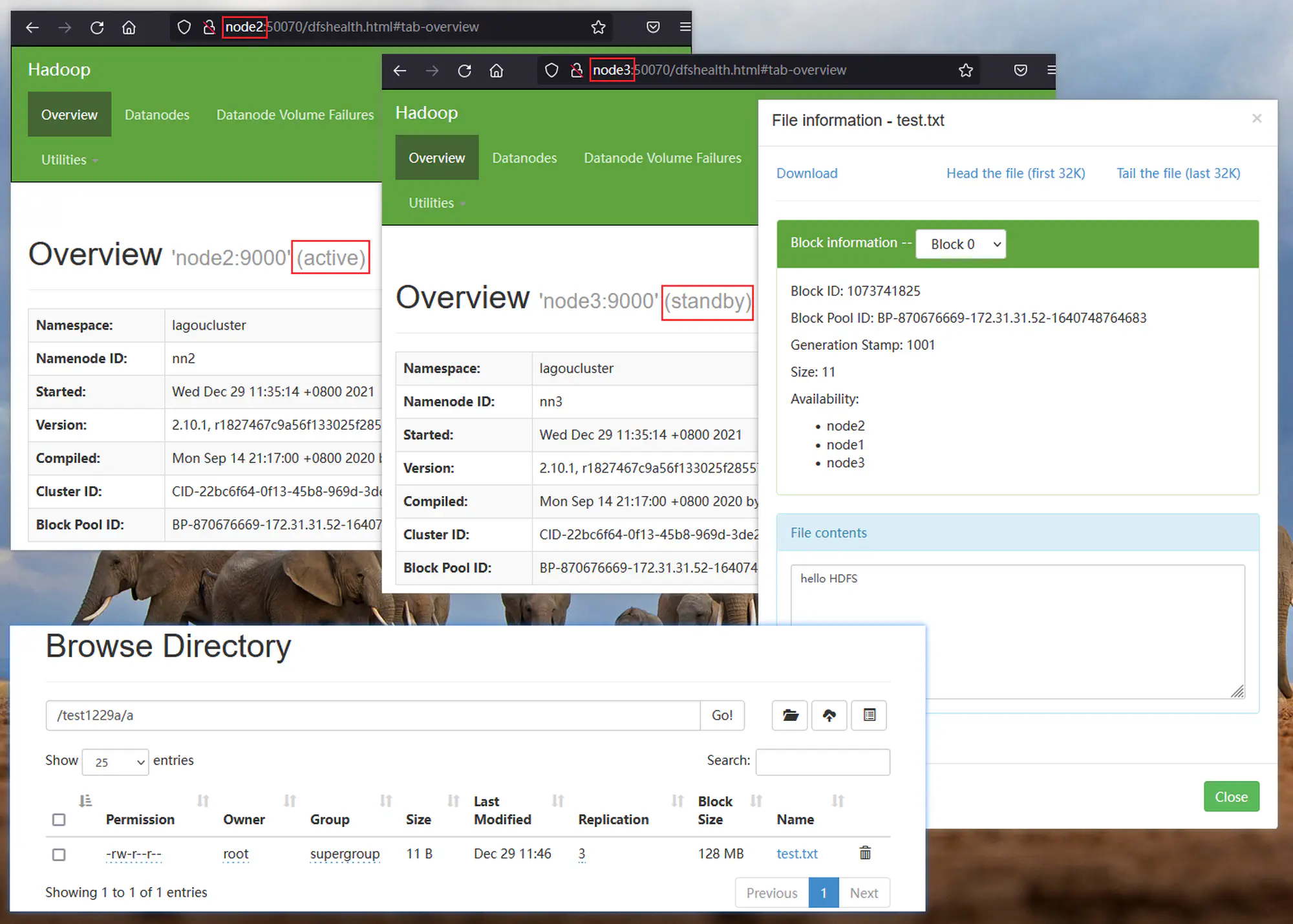
5.3.3 启动 YARN
|
|
关停操作(反序)
|
|
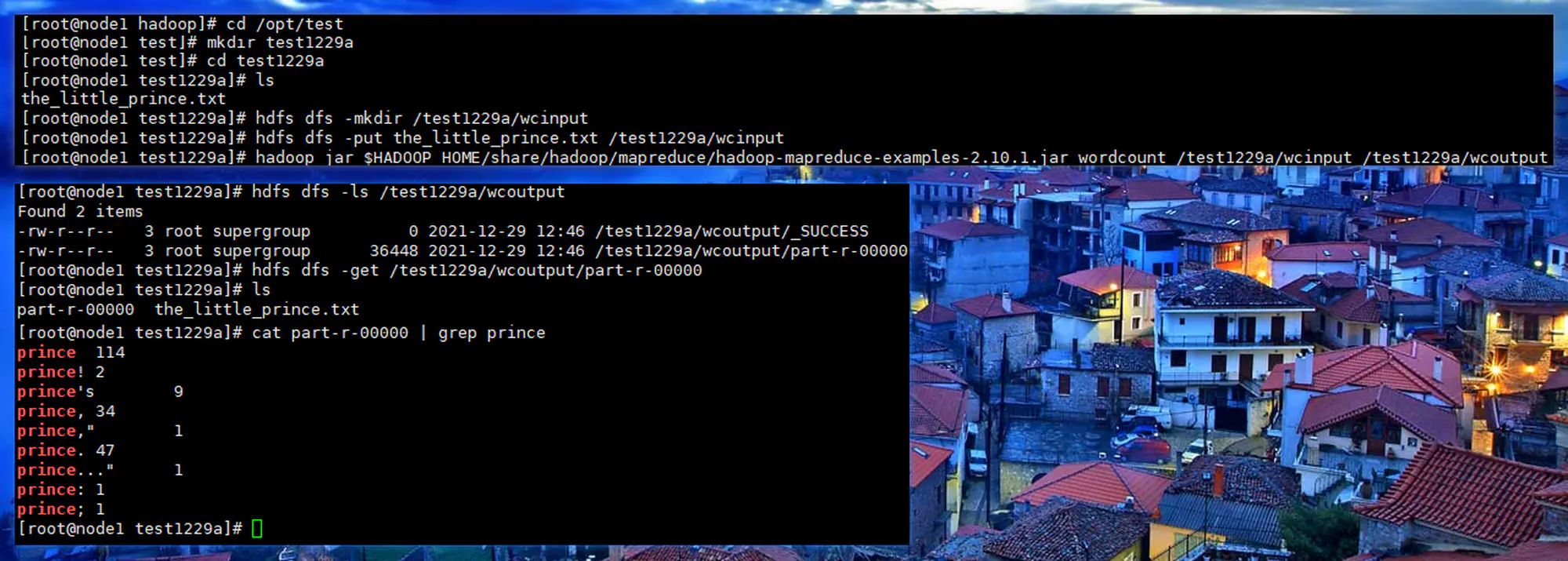
5.3.4 验证 YARN 和 MR
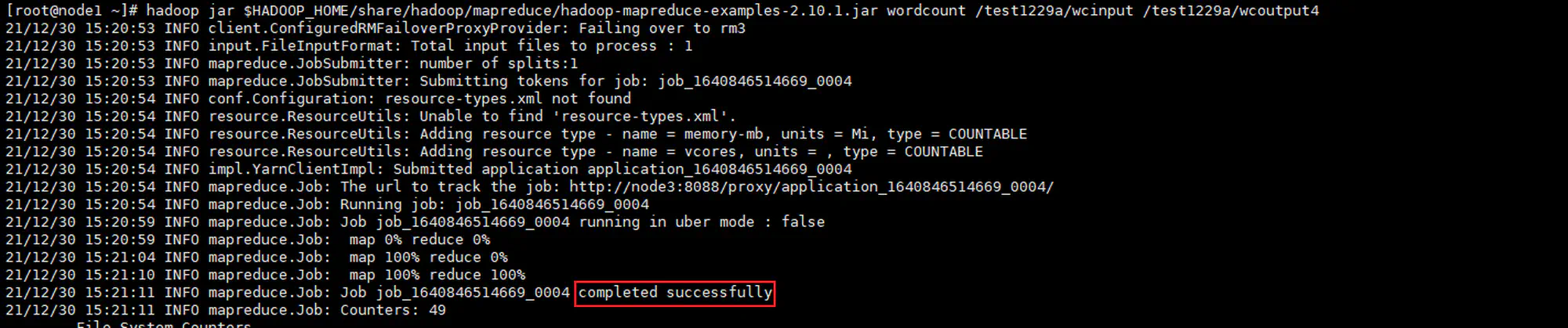
使用 Hadoop 内置的 wordcount 示例程序,对 《小王子》(英文版)进行计算
|
|
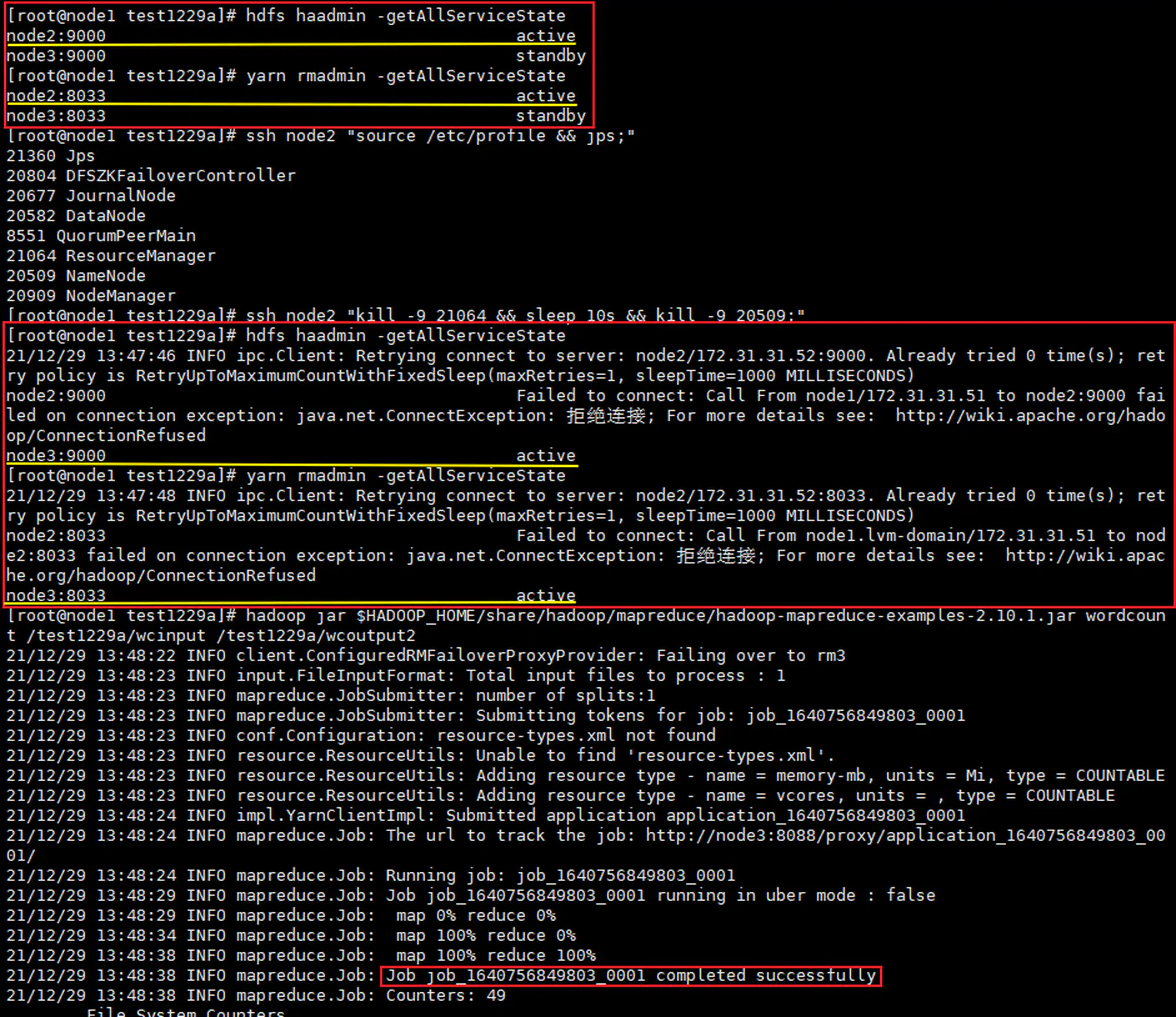
5.3.5 验证 HA 功能
|
|
关机,快照 004
6 安装 Hive
6.1 规划
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
| »> HIVE(远程部署模式): | |||
| MetadataDB(MySQL) | ✔ | ✘ | ✘ |
| Hive Client(非常驻) | ✔ | ✔ | ✔ |
| Metastore | ✔ | ✘ | ✘ |
| HiveServer2(用到再装) | (✔) | ✘ | ✘ |
| Beeline Client(非常驻,可连H2) | (✔) | (✔) | (✔) |
| HCatalog(非常驻,不常用) | (✔) | (✔) | (✔) |
6.2 安装 MySQL
安装过程(略)
关机,快照 004a(单独这台)
6.3 建库、用户及授权
创建用于存放 Hive 元数据的库,及用于连接该库的用户,并进行授权:
|
|
6.4 安装 HIVE
6.4.1 下载解压
|
|
6.4.2 上传 jdbc 驱动文件、删除重复的 log4j
|
|
6.4.3 修改 Hive 日志输出目录
-
默认的日志文件存放在:
/tmp/<当前用户名> -
1 2 3 4 5 6 7 8mkdir -p /opt/logs/hive cd /opt/apps/hive-2.3.9/conf/ ls cp hive-log4j2.properties.template hive-log4j2.properties ls nano hive-log4j2.properties # 修改下面这行 -
修改这行:
-
1 2#property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} property.hive.log.dir = /opt/logs/hive
-
6.4.4 创建、编写 hive-site.xml 配置文件
-
1nano /opt/apps/hive-2.3.9/conf/hive-site.xml -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 操作小规模数据时,使用本地模式,提高效率 --> <property> <name>hive.exec.mode.local.auto</name> <value>true</value> <description>Let Hive determine whether to run in local mode automatically</description> </property> <!-- hive 元数据的数据库连接 --> <!-- hive 元数据的存储位置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hivemetadata?useUnicode=true&characterEncoding=utf8&useSSL=false</value> <description>JDBC connect string for a JDBC metastore</description> </property> <!-- 指定驱动程序 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <!-- 连接数据库的用户名 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <!-- 连接数据库的口令 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>12345678</value> <description>password to use against metastore database</description> </property> <!-- HIVE 数据默认的存储位置(HDFS) --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> <!-- 在 Hive CLI 中,显示当前操作的数据库 --> <property> <name>hive.cli.print.current.db</name> <value>true</value> <description>Whether to include the current database in the Hive prompt.</description> </property> <!-- 在 Hive CLI 中,显示数据的表头 --> <property> <name>hive.cli.print.header</name> <value>true</value> </property> </configuration> -
1 2# 同步到其他主机 $CS/rsync.sh /opt/apps/hive-2.3.9
6.4.5 设置环境变量
|
|
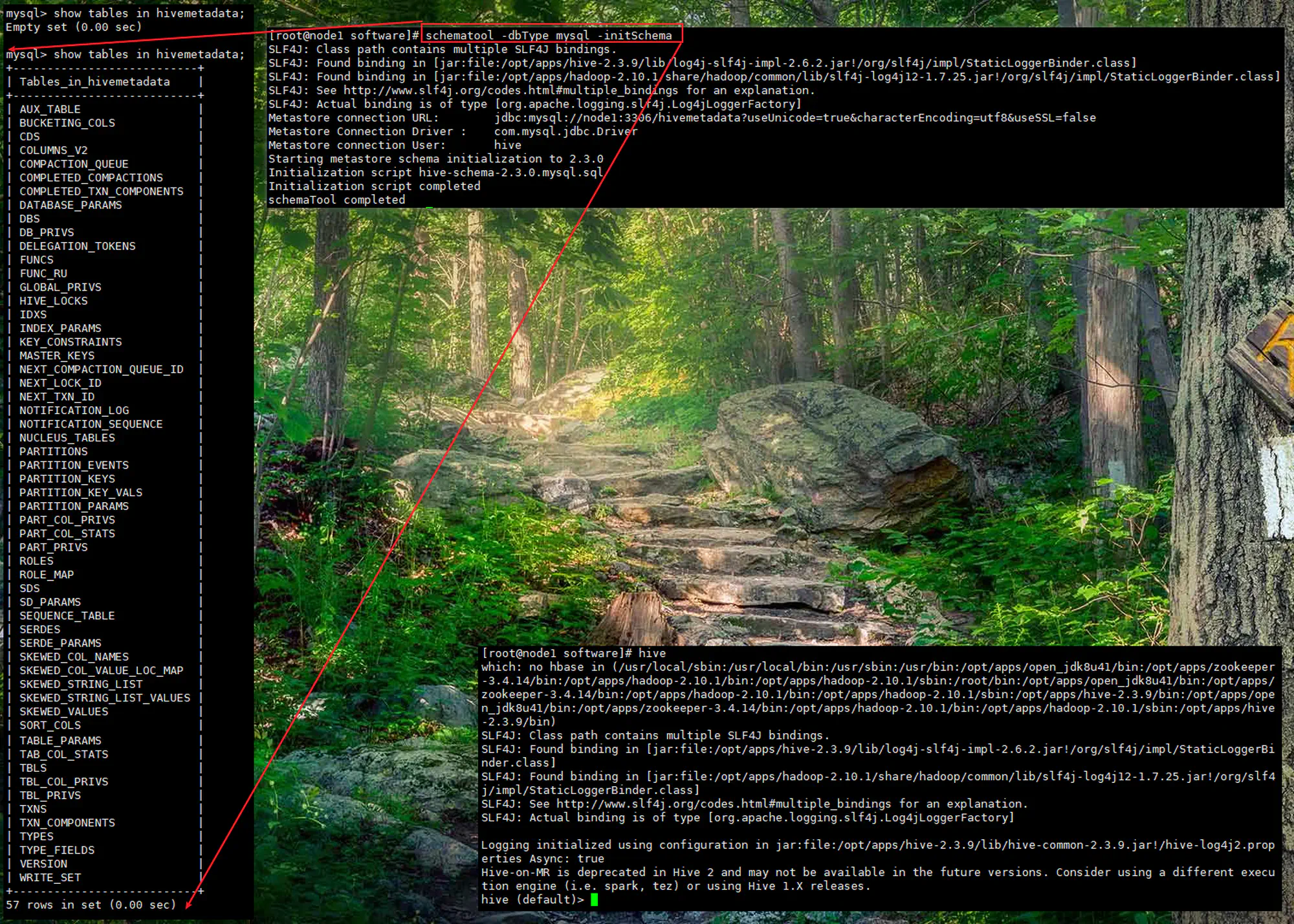
6.5 初始化及验证(本地模式)
-
初始化元数据库
-
1schematool -dbType mysql -initSchema -
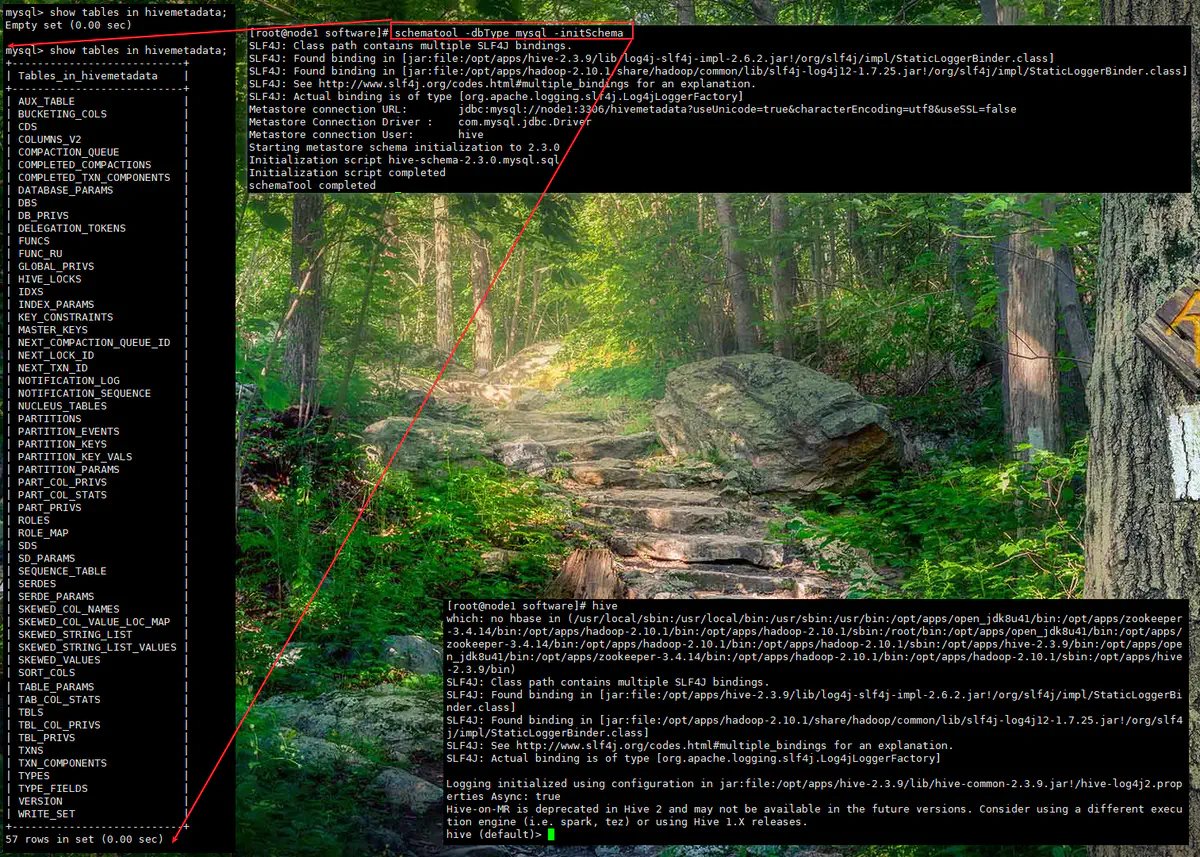
013
-
-
测试
-
1 2 3 4 5 6 7 8 9 10 11 12create table test.test1( id int, name string ); select * from test.test1; insert into test.test1 values (1001,'adam'), (1002,'ben'); select * from test.test1;
-
6.6 配置 “远程模式部署”
6.6.1 给 hive metastore 服务单独创建一份配置文件
-
1 2 3 4 5 6 7 8 9mkdir -p /opt/conf/hive_metastore_conf mkdir -p /opt/logs/hive/metastore cp /opt/apps/hive-2.3.9/conf/hive-site.xml /opt/conf/hive_metastore_conf/hive-site.xml cp /opt/apps/hive-2.3.9/conf/hive-log4j2.properties /opt/conf/hive_metastore_conf/hive-log4j2.properties nano /opt/conf/hive_metastore_conf/hive-site.xml nano /opt/conf/hive_metastore_conf/hive-log4j2.properties -
hive-site.xml只保留 “连接存储元数据的数据库” 部分-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25<!-- hive 元数据的数据库连接 --> <!-- hive 元数据的存储位置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hivemetadata?useUnicode=true&characterEncoding=utf8&useSSL=false</value> <description>JDBC connect string for a JDBC metastore</description> </property> <!-- 指定驱动程序 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <!-- 连接数据库的用户名 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <!-- 连接数据库的口令 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>12345678</value> <description>password to use against metastore database</description> </property>
-
-
hive-log4j2.properties另外指定一下日志输出目录-
1 2#property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} property.hive.log.dir = /opt/logs/hive/metastore
-
6.6.2 修改 Hive 客户端的配置文件(默认路径里的配置文件)
-
1nano /opt/apps/hive-2.3.9/conf/hive-site.xml -
去掉 “连接存储元数据的数据库” 部分,替换为连接 metastore 服务的设置
-
1 2 3 4 5 6<!-- hive metastore 服务地址 --> <property> <name>hive.metastore.uris</name> <!-- <value>thrift://node2:9083,thrift://node3:9083</value> --> <value>thrift://node1:9083</value> </property>
-
-
同步到其他节点
-
1$CS/rsync.sh /opt/apps/hive-2.3.9/conf/hive-site.xml
-
6.7 启动和验证(远程模式)
-
启动 zookeeper 、hadoop(略)
-
启动 hive metastore 服务
-
1hive --config /opt/conf/hive_metastore_conf/ --service metastore -
该进程占用终端(可使用
nohup或screen实现后台运行)
-
-
分别在 node1 、node2 、node3 上启动 hive 并执行操作
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14create table test.test10( id int, name string ); select * from test.test10; insert into test.test10 values (1001,'adam'), (1002,'ben'); select * from test.test10; -- 改表名执行
-
-
查看连接

014 - 可以看到,3 个客户端 连接了 hive metastore 的 9083 端口

关机,快照 005
7 安装 Tez
7.1 规划
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
| »> Tez(无后台服务): | ✔ | ✔ | ✔ |
7.2 安装
7.2.1 下载解压
|
|
7.2.2 上传 tez.tar.gz 到 hdfs 上
|
|
7.2.3 创建、编写 tez-site.xml 配置文件
-
1 2 3ls $HADOOP_HOME/etc/hadoop/ touch $HADOOP_HOME/etc/hadoop/tez-site.xml nano $HADOOP_HOME/etc/hadoop/tez-site.xml -
写入如下内容:
-
1 2 3 4 5 6 7 8 9 10<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定在 hdfs 上的 tez 包文件 --> <property> <name>tez.lib.uris</name> <value>hdfs://hdfscluster/user/tez/tez.tar.gz</value> </property> </configuration>
-
7.2.4 删除重复的 log4j
|
|
7.2.5 设置环境变量
|
|
7.2.6 同步及验证环境变量
|
|
7.3 验证
(配置完 Tez 后,需要重启集群)
7.3.1 验证 Hive on Tez
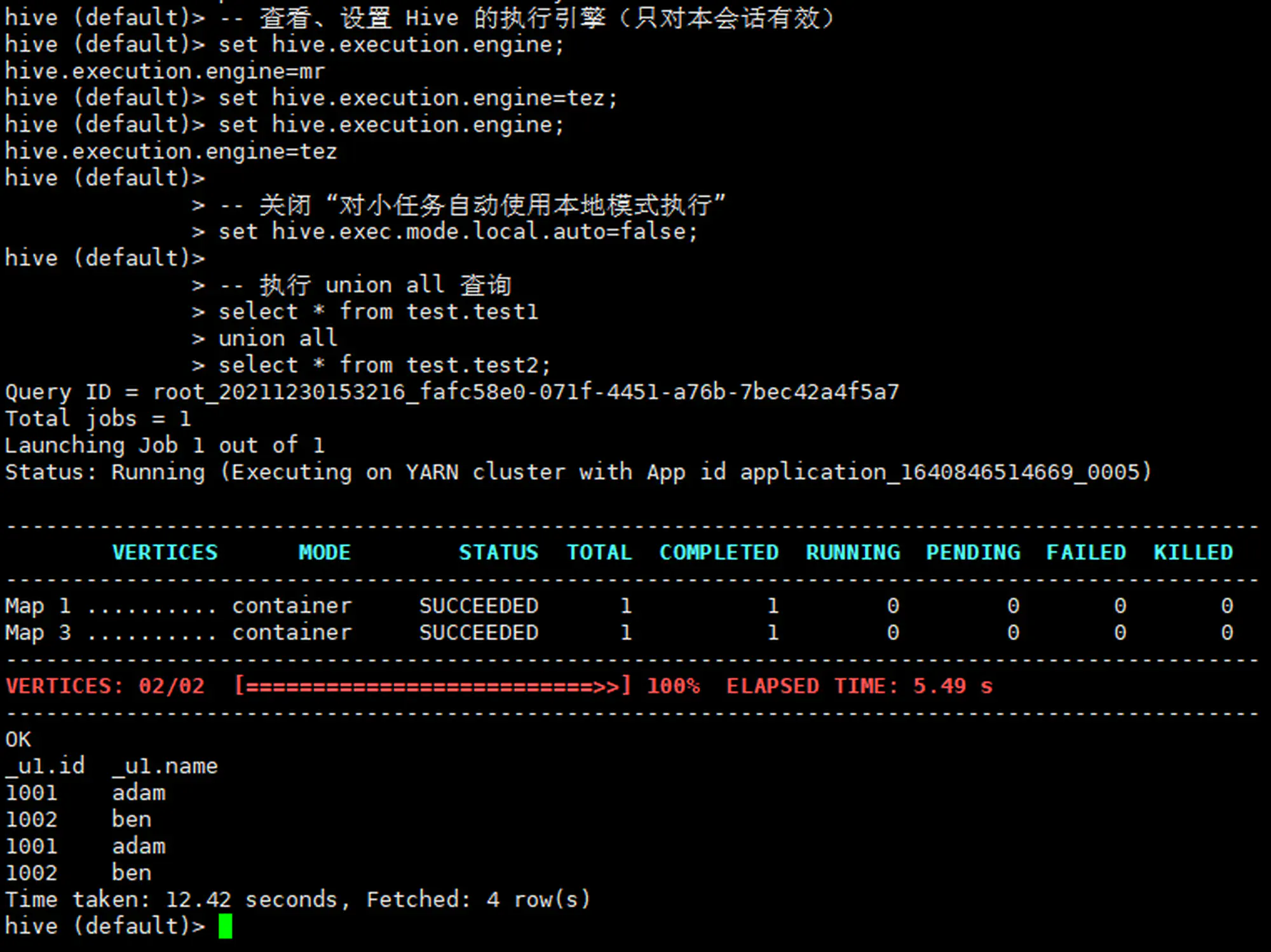
-
1 2 3 4 5 6 7 8 9 10 11 12-- 查看、设置 Hive 的执行引擎(只对本会话有效) set hive.execution.engine; set hive.execution.engine=tez; set hive.execution.engine; -- 关闭 “对小任务自动使用本地模式执行” set hive.exec.mode.local.auto=false; -- 执行 union all 查询 select * from test.test1 union all select * from test.test2; -
测试的时候遇到了
AM Container is running beyond virtual memory limits的错误-
解决方法:修改
yarn-site.xml配置文件,将虚拟内存比例调大到 5 ,默认是 2.1,参考 -
1 2nano $HADOOP_HOME/etc/hadoop/yarn-site.xml # 添加下面的属性 -
1 2 3 4 5<property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5</value> <description>Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.</description> </property>
-
-
再次重启集群、测试
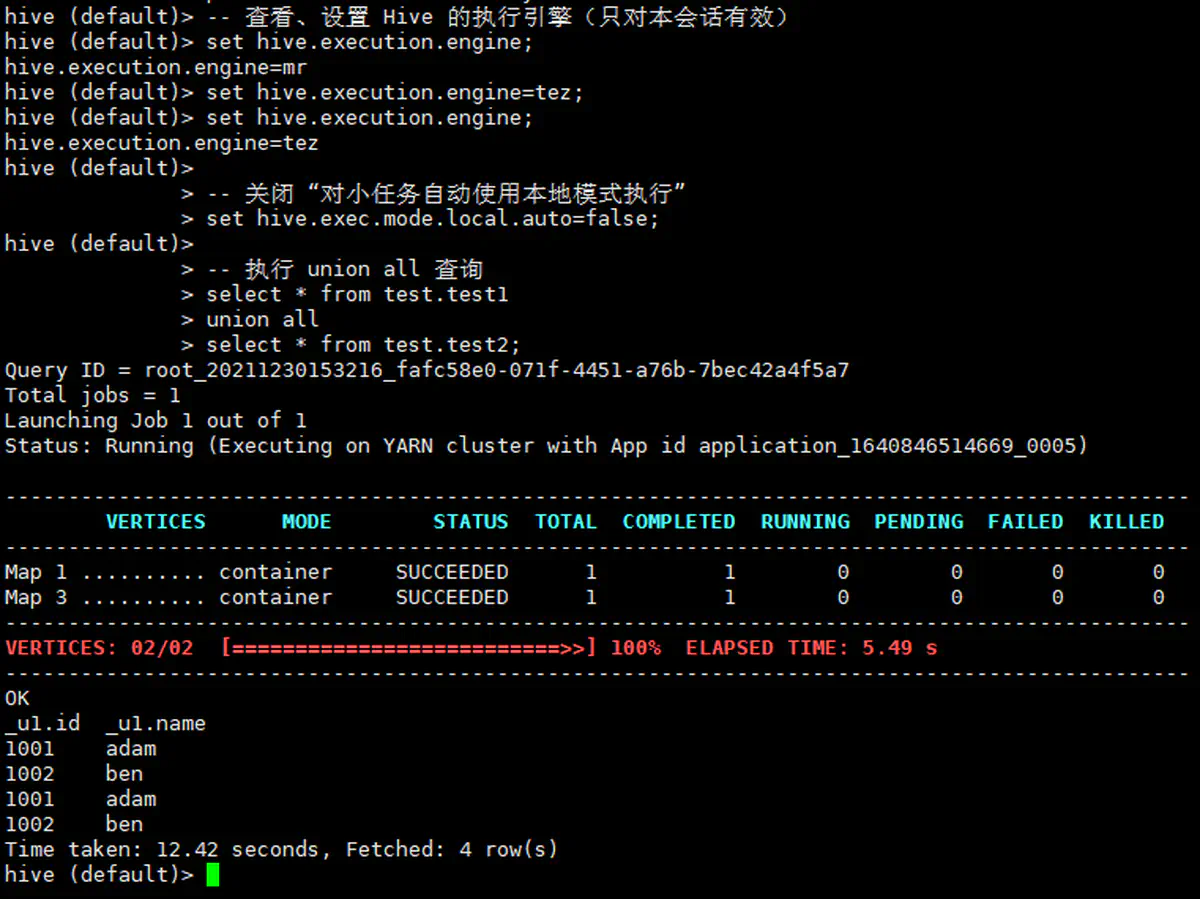
015
7.3.2 验证 wordcount 程序
|
|
Tez wordcount:
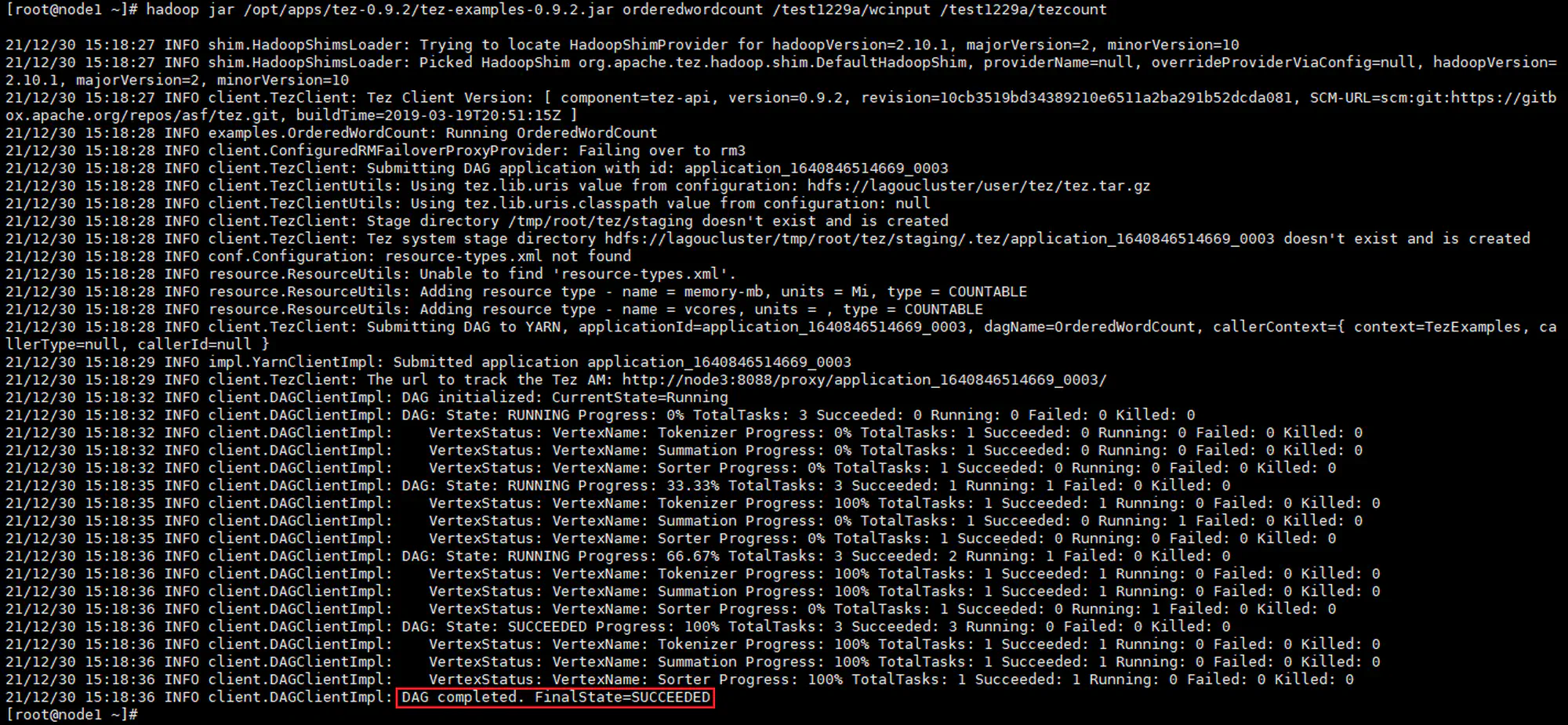
MapReduce wordcount:
关机,快照 006
8 安装 Flume
8.1 规划
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
| »> Flume(无后台服务): | ✔ | ✔ | ✔ |
8.2 安装
8.2.1 下载解压
|
|
8.2.2 修改 flume-env.sh 配置文件
|
|
指定 JDK 环境变量:
|
|
8.2.3 修改 log4j.properties 配置文件
|
|
指定日志输出的目录:
|
|
8.2.4 设置环境变量
|
|
8.2.5 同步及验证环境变量
|
|
8.3 验证
-
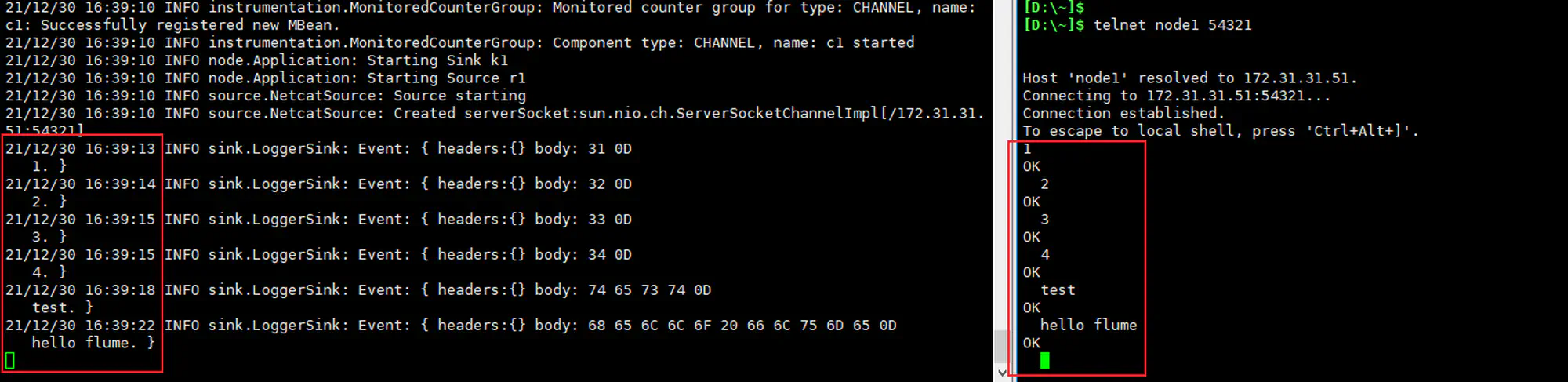
编写一个最简单的 Agent 配置文件
-
1 2 3mkdir -p /opt/conf/flume_agents cd /opt/conf/flume_agents/ nano flume_demo_netcat_logger.conf -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19# a1是agent的名称。source、channel、sink的名称分别为:r1 c1 k1 a1.sources = r1 a1.channels = c1 a1.sinks = k1 # source a1.sources.r1.type = netcat a1.sources.r1.bind = node1 a1.sources.r1.port = 54321 # channel a1.channels.c1.type = memory # sink a1.sinks.k1.type = logger # source、channel、sink之间的关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
-
-
启动 Agent
-
1 2 3flume-ng agent --name a1 \ --conf-file /opt/conf/flume_agents/flume_demo_netcat_logger.conf \ -Dflume.root.logger=INFO,console -
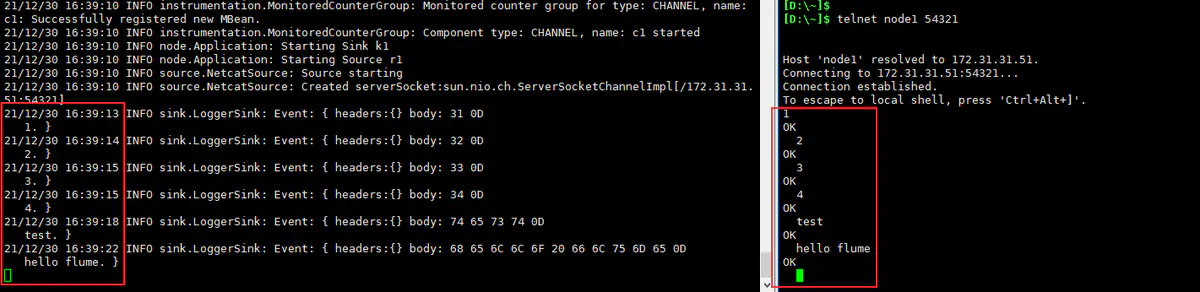
018
-
关机,快照 007
9 安装 DataX
9.1 规划
| 虚拟机 | Cluster_Node1 | Cluster_Node2 | Cluster_Node3 |
|---|---|---|---|
| 整体规划 | 单独安装的应用 + 全部安装的应用 |
HA1 + 全部安装的应用 |
HA2 + 全部安装的应用 |
| »> DataX(无后台服务): | ✔ | ✔ | ✔ |
9.2 安装
9.2.1 下载解压
|
|
可能是发布方用苹果电脑打包的时候不注意,每个目录都多了个 ._<目录名> 的伴随文件,这会导致使用的时候报类似 datax/plugin/reader/._drdsreader/plugin.json]不存在 的错误。
把这些 ._<目录名> 文件删除就好:
|
|
移动到 /opt/apps 目录
|
|
9.2.2 设置环境变量
|
|
9.2.3 同步及验证环境变量
|
|
9.3 验证
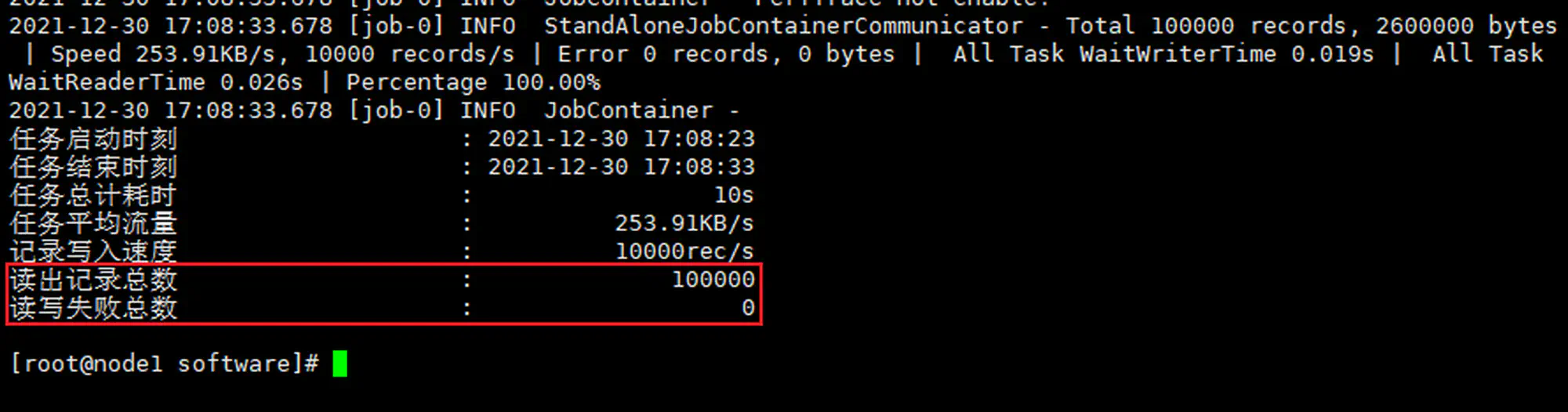
使用 DataX 预设的一个用于自检的 job 配置进行验证:
|
|
关机,快照 008
10 附录:脚本
10.1 all.sh
|
|
10.2 rsync.sh
|
|
10.3 poweroff.sh
|
|
10.4 reboot.sh
|
|
10.5 du.sh
|
|