
MySQL笔记_1_基础_1
MySQL笔记_1_基础_1
1 MySQL 基础知识
结构化查询语言(Structured Query Language)简称 SQL ,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
用于管理关系数据库管理系统(RDBMS),或在关系流数据管理系统(RDSMS)中进行流处理。
SQL 基于关系代数和元组关系演算,包括数据定义语言和数据操纵语言。SQL 包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。尽管 SQL 经常被描述为,而且很大程度上是一种声明式编程(4GL),但是其也含有过程式编程的元素。
SQL 在 1986 年成为美国国家标准学会(ANSI)的一项标准,在 1987 年成为国际标准化组织(ISO)标准。此后,这一标准经过了一系列的增订,加入了大量新特性。虽然有这一标准的存在,但大部分的 SQL 代码在不同的数据库系统中并不具有完全的跨平台性。
1.1 常见的数据库
-
MySql数据库
- 因免费开源、运作简单的特点,常作为中小型项目的数据库首选
- MySQL 始于 1996 年,08 年被 SUN 收购,09 年 SUN 被 Oracle 收购(从此,甲骨文拥有全球第一第二两款数据库软件)。
- 从版本 6 开始,甲骨文开始对MySQL收费(但同时发行免费的社区版)
-
MariaDB
- CentOS 的默认数据库
- 始于 09 年,MySQL 被收购后,业界当心其开源前景,开发了 MariaDB
- 乌尔夫·米卡埃尔·维德纽斯(瑞典语:Ulf Michael Widenius,1962年3月3日-),常昵称作蒙提(Monty),芬兰程序员与企业家,开放源代码数据库 MySQL 的主要设计者,同时也是MySQL AB公司的创始成员和现任MariaDB的首席技术官。
- MariaDB 是以 Monty 的小女儿 Maria 命名的,而 MySQL 是以他另一个女儿 My 命名的。
-
PostgreSQL
- 另一款开源免费的数据库,相比 MySQL ,提供更多大型数据库所需的功能
-
SQLite
- 与许多其它数据库管理系统不同,SQLite 不是一个客户端/服务器结构的数据库引擎,而是被集成在用户程序中。
- 它作为嵌入式数据库,是应用程序(如网页浏览器)在本地/客户端存储数据的常见选择。它可能是最广泛部署的数据库引擎,因为它正在被一些流行的浏览器、操作系统、嵌入式系统所使用。
-
MS SQL Server
- 微软的商业数据库
- 只能运行在 windows 平台上
-
Oracle 数据库
- 收费的大型数据库,Oracle 公司的核心产品。
- 安全性高,性能强,功能多
-
DB2
- IBM 的商业数据库,支持超大型数据库
- 常在银行系统中使用
-
mongoDB
- 非关系型数据库
1.2 db-engines.com 数据库排行(2021年5月)
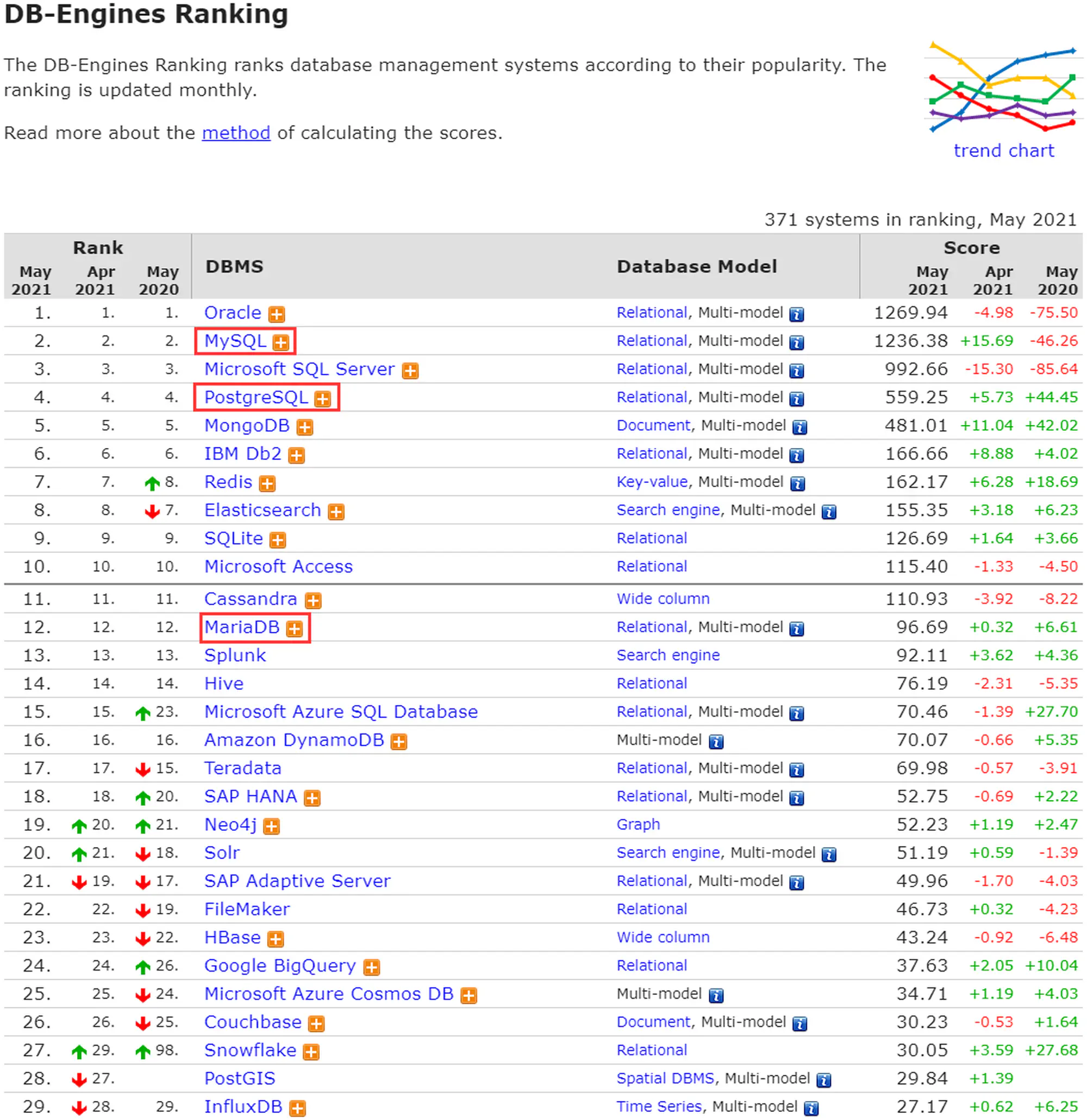
1.数据库排行)
1.3 MySql 的目录结构(以 Windows 下为例)
1.3.1 MySql的默认安装目录
C:\Program Files\MySQL\MySQL Server 5.7,其中:
bin目录- 该目录配置环境变量后,可以使用
mysql命令 - 放置一些可执行文件
- 该目录配置环境变量后,可以使用
docs目录- 文档
include目录- 包含(头)文件
lib目录- 依赖库
share目录- 用于存放字符集、语言等信息。
1.3.2 MySQL配置文件与数据存放目录
C:\ProgramData\MySQL\MySQL Server 5.7
my.ini文件- 配置文件
Data目录- 最重要:存放数据库、表,数据目录
2 SQL 语句
SQL 语句
- 是所有关系型数据库的统一查询规范,不同的关系型数据库都支持 SQL
- 所有的关系型数据库都可以使用 SQL
- 不同数据库之间的 SQL ,可能存在一些区别,类似方言
2.1 SQL 通用语法
-
SQL 语句可以 “单行” 或 “多行” 书写,以
;结尾 (Sqlyog 会自动添加分号) -
可以使用空格和缩进来增加语句的可读性
-
MySql 中使用的 SQL 不区分大小写,一般关键字大写,数据库名、表名、列名小写
-
注释方式
-
1 2 3 4 5 6# show databases; 单行注释 -- show databases; 单行注释(-- 后面必须要有空格) /* 多行注释 show databases; */
-
2.2 SQL 语句的分类
| 分类 | 说明 |
|---|---|
| 数据定义语言 DDL (Data Definition Language) |
用来定义数据库对象:数据库,表,列等 |
| 数据操作语言 DML (Data Manipulation Language) |
用来对数据库中表的记录进行更新 |
| 数据查询语言 DQL (Data Query Language) |
用来查询数据库中表的记录 |
| 数据控制语言 DCL (Date Control Language) |
用来控制数据库的访问权限和安全级别,及创建用户 |
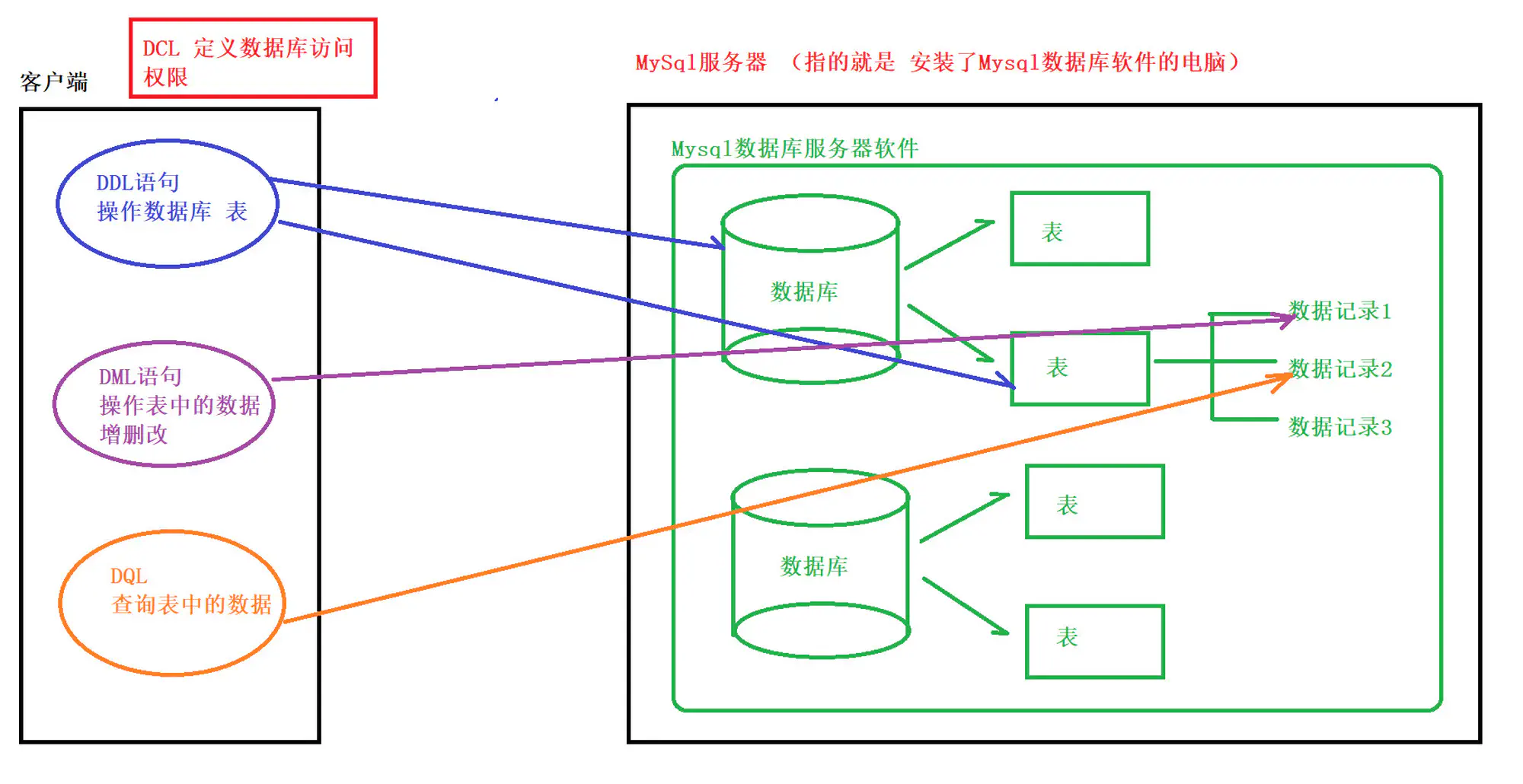
2.SQL 语句分类)
2.3 DDL 操作数据库
|
|
2.3.1 MySQL 预设数据库

3.预设数据库)
|
|
2.4 DDL 操作数据表
2.4.1 MySQL 中常见的数据类型
| 类型 | 描述 |
|---|---|
| int | 整型 |
| double | 浮点型 |
| varchar | 字符串型 |
| date | 日期类型,给是为 yyyy-MM-dd ,只有年月日,没有时分秒 |

4.char与varchar类型)完整数据类型
2.4.2 DDL 创建、查看表
|
|
2.4.3 DDL 删除表
|
|
2.4.4 DDL 修改表
|
|
2.5 DML 操作数据(重点)
2.5.1 DML 插入数据
|
|
2.5.2 DML 修改数据
|
|
2.5.3 DML 删除数据
|
|
2.6 DQL 查询数据(重点)
2.6.1 DQL 简单查询
|
|
2.6.2 DQL 条件查询
模糊查询 通配符
| 通配符 | 说明 |
|---|---|
| % | 表示匹配任意多个字符串 |
| _ | 表示匹配 一个字符 |
比较运算符
| 运算符 | 说明 |
|---|---|
| >, <, <=, >=, =, <>, != | 大于、小于、大于(小于)等于、不等于 |
| BETWEEN …AND… | 显示在某一区间的值 例如: 2000-10000之间: Between 2000 and 10000 |
| IN(集合) | 集合表示多个值,使用逗号分隔,例如: name in (悟空,八戒) in 中的每个数据都会作为一次条件,只要满足条件就会显示 |
| LIKE ‘%张%’ | 模糊查询 |
| IS NULL | 查询某一列为NULL的值, 注: 不能写 = NULL |
逻辑运算符
| 运算符 | 说明 |
|---|---|
| And && | 多个条件同时成立 |
| Or || | 多个条件任一成立 |
| Not | 不成立,取反 |
|
|
3 DQL 单表查询
3.0.3 DQL 排序查询
- 通过 ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示效果,不会影响真实数据)
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]ASC表示升序排序(默认)DESC表示降序排序
- 单列排序
- 只按照某一个字段进行排序, 就是单列排序
- 组合排序
- 同时对多个字段进行排序,如果第一个字段相同,就按照第二个字段进行排序,依此类推
|
|
3.0.4 DQL 聚合函数
- 之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对某一列的值进行计算,然后返回一个单一的值
- 另外聚合函数会忽略 NULL 空值
- 语法结构:
SELECT 聚合函数(字段名) FROM 表名;
| 聚合函数 | 作用 |
|---|---|
| count(字段) | 统计指定列不为 NULL 的记录行数 |
| sum(字段) | 计算指定列的数值和 |
| max(字段) | 计算指定列的最大值 |
| min(字段) | 计算指定列的最小值 |
| avg(字段) | 计算指定列的平均值 |
|
|
3.0.5 DQL 分组查询
- 分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
- 语法格式:
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件]
3.0.5.1 图解 GROUP BY 分组的过程

5.分组过程)注意
- 分组时可以查询要分组的字段,或者使用聚合函数进行统计操作
- 查询其他字段没有意义
|
|
3.0.5.2 where 与 having的区别
- where
- where 进行分组前的过滤
- where 后面不能写聚合函数
- having
- having 是分组后的过滤
- having 后面可以写聚合函数
3.0.6 limit关键字
- limit 是限制的意思,用于限制返回的查询结果的行数(可以通过limit指定查询多少行数据)
- limit 语法是 MySql 的方言,用来完成分页
- 语法结构:
SELECT 字段1,字段2... FROM 表名 LIMIT offset, length;- limit offset, length;
- 关键字可以接受一个或者两个为 0 或者正整数的参数
- offset
- 起始行数, 从0开始记数, 如果省略 则默认为 0.
- length
- 返回的行数
- limit offset, length;
|
|
4 约束
约束的作用:
- 对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性。
- 违反约束的不正确数据,将无法插入到表中
4.0.7 常见的约束
| 约束名 | 约束关键字 | 特点 | 作用 |
|---|---|---|---|
| 主键 | PRIMARY KEY | 唯一 非空 一个表只有一个主键 |
用来表示数据库中的每一条记录 |
| 唯一 | UNIQUE | 唯一 | |
| 非空 | NOT NULL | 该列不允许为空 | |
| 默认值 | DEFAULT | 设置该列默认值 | |
| 外键 | Foreign KEY |
4.0.8 主键约束
-
用途
- 通常针对业务去设计主键,每张表都设计一个主键 id
- 主键是给数据库和程序使用的,跟最终的客户无关,所以主键没有意义没有关系,只要能够保证不重复就好,比如身份证就可以作为主键。
-
语法格式
字段名 字段类型 primary key
|
|
4.0.8.1 删除主键约束
|
|
4.0.8.2 主键的自增
|
|
4.0.8.3 修改主键自增的起始值
- 默认地 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下面的方式
|
|
4.0.8.4 DELETE 和 TRUNCATE 对自增长的影响
- DELETE
- 只是删除表中所有数据,对自增没有影响
- TRUNCATE
- truncate 是将整个表删除掉,然后创建一个新的表
- 自增的值,重新从 1 开始
- 即使之前设置过起始值,也会从 1 开始
|
|
4.0.9 非空约束
|
|
4.0.10 唯一约束
|
|
4.0.11 主键约束和唯一约束的区别
- 主键约束和唯一约束的区别
- 主键约束:唯一,不能为空
- 唯一约束:唯一,可以为空
- 一个表中只能有一个主键,但是可以有多个唯一约束
4.0.12 默认值
|
|
5 MySQL 多表、外键
5.1 多表
- 单表的问题
- 数据记录不做分类,大量空字段
- 检索、查看数据不方便
- 冗余,同一个字段中出现大量的重复数据
- 多表的问题
- 当我们在员工表的 dept_id 里面输入不存在的部门 id ,数据依然可以添加,显然这是不合理的
- 实际上我们应该保证,员工表所添加的 dept_id ,必须在部门表中存在
- 外键约束就是为此而设计
5.2 外键约束
- 外键指的是在从表中与主表的主键对应的那个字段,比如员工表的 dept_id ,就是外键
- 多表关系中的主表和从表
- 主表:主键 id 所在的表,约束别人的表
- 从表:外键所在的表,被约束的表
- 多表关系中的主表和从表
- 使用外键约束可以让两张表之间产生一个对应关系,产生强制性的外键数据检查,从而保证了数据的完整性和一致性,
5.2.1 创建外键约束
- 新建表时添加外键
[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
- 已有表添加外键
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主 键字段名);- 可以省略外键名称, 系统会自动生成一个
ALTER TABLE employee ADD FOREIGN KEY (dept_id) REFERENCES department (id);
|
|
5.2.2 删除外键约束
alter table 从表 drop foreign key 外键约束名称
|
|
注意
- 从表外键类型必须与主表主键类型一致,否则创建失败
- 添加数据时,应该先添加主表中的数据
- 删除数据时,应该先删除从表中的数据
5.2.3 级联删除操作(慎用、了解)
- 如果想实现删除主表数据的同时,也删除掉相关的从表数据,可以使用级联删除
- 级联删除的使用
- 在添加外键约束的同时,添加级联删除
ON DELETE CASCADE
- 在添加外键约束的同时,添加级联删除
|
|
5.3 表与表之间的三种关系
-
一对多关系
- 最常见的关系,学生对班级,员工对部门
-
多对多关系
- 学生与课程,用户与角色
-
一对一关系
- 使用较少,因为一对一关系可以合成为一张表
5.3.1 一对多
一对多建表原则 在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键
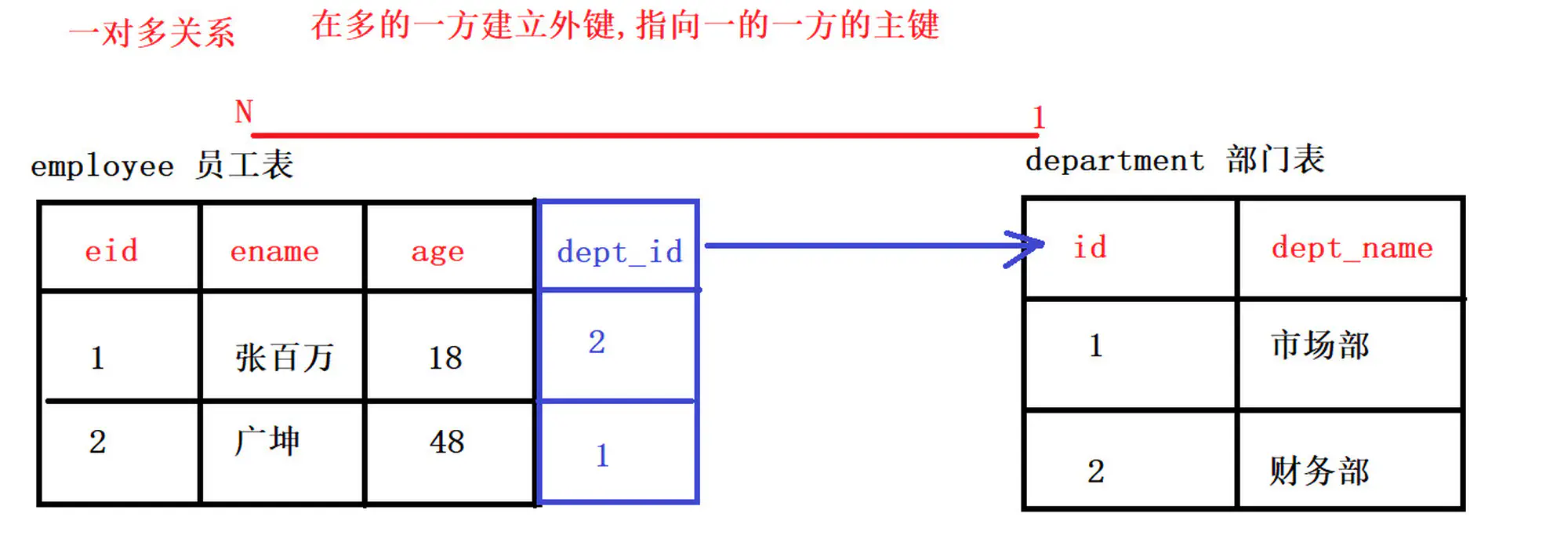
6.一对多)
|
|
5.3.2 多对多
多对多建表原则 需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的 主键。
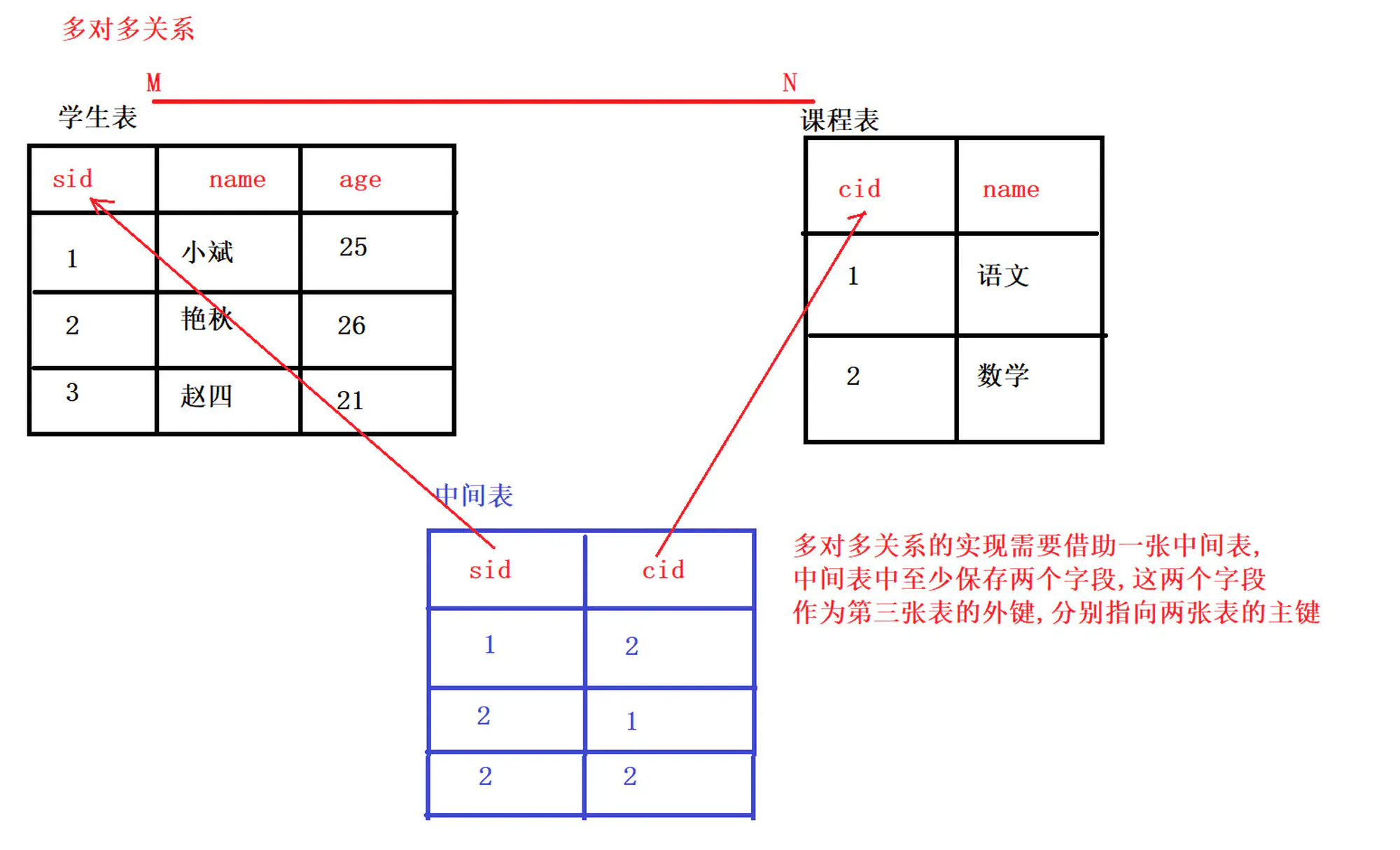
7.多对多)
|
|
5.3.3 一对一
一对一建表原则: 外键唯一,主表的主键和从表的外键(唯一),形成主外键关系,外键唯一:UNIQUE
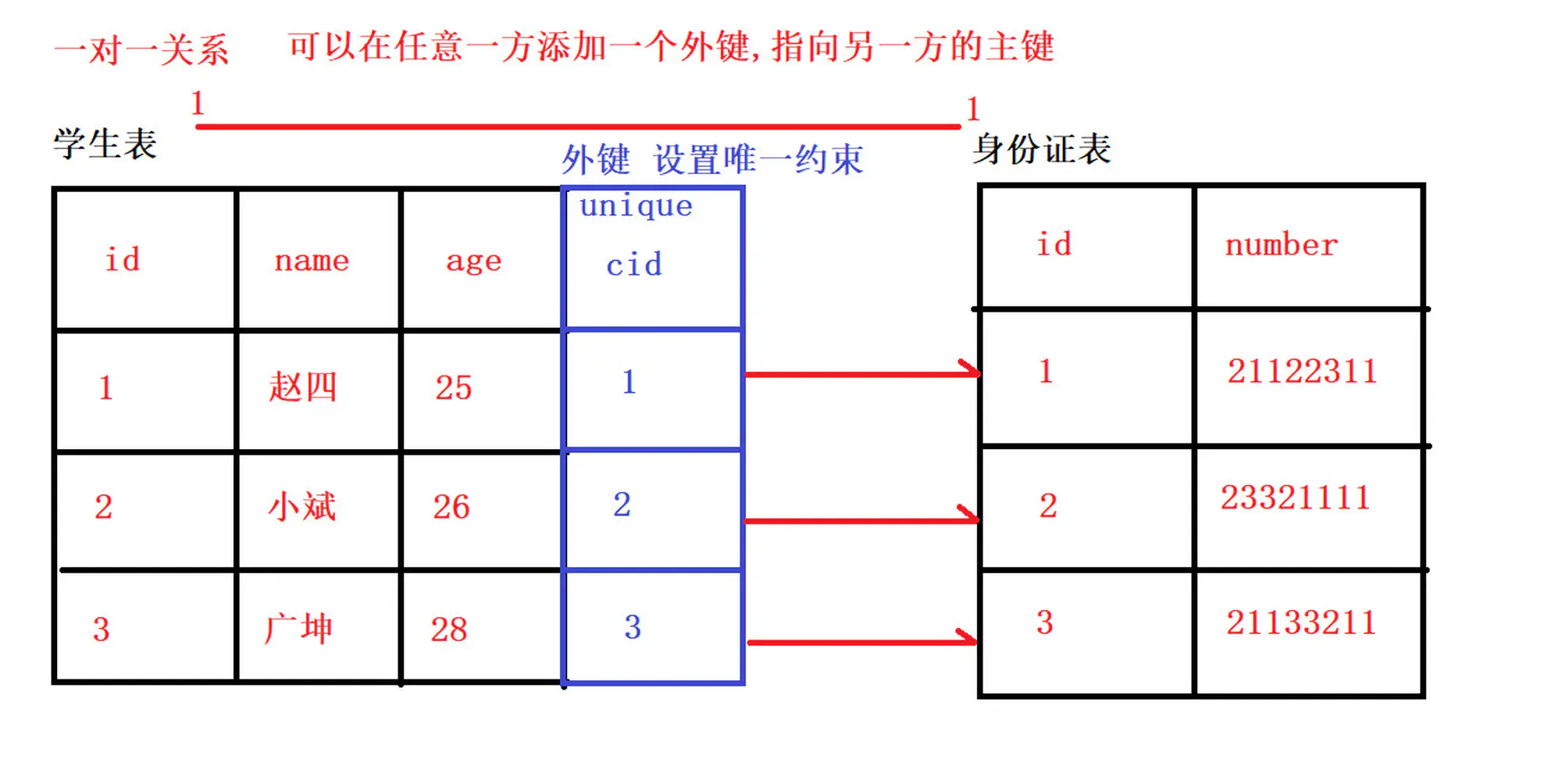
8.一对一)
5.4 DQL 多表查询
5.4.1 数据准备
|
|
5.4.2 笛卡尔积
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为 {(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
|
|
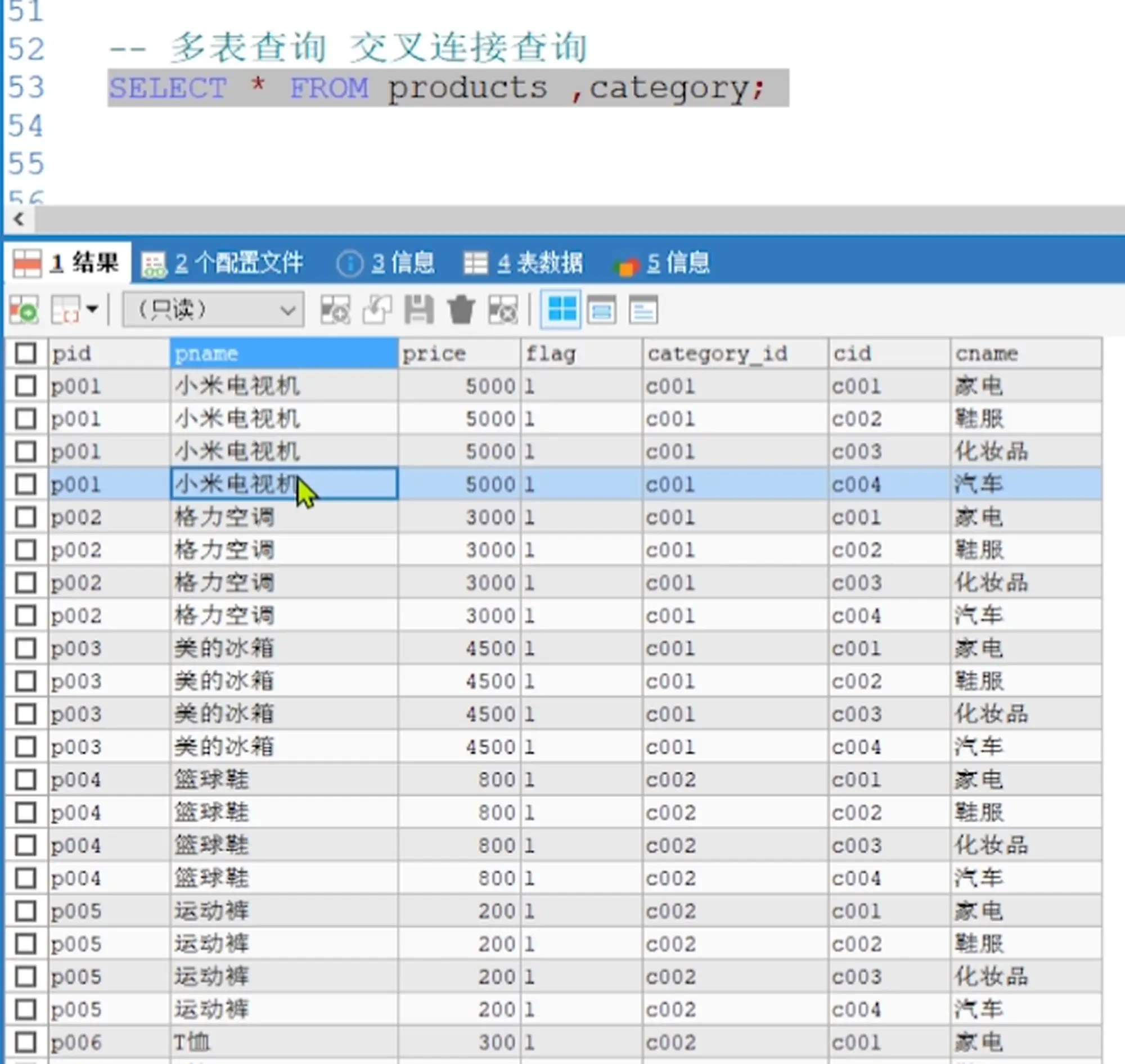
9.笛卡尔积)
5.4.3 内连接查询
通过指定的条件去匹配两张表中的数据,匹配上就显示,匹配不上就不显示
5.4.4 隐式内连接
SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
|
|
5.4.5 显式内连接
SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件
|
|
5.4.6 左外连接查询
以左表为基准,匹配右边表中的数据
如果匹配的上,就展示匹配到的数据
如果匹配不到,左表中的数据正常展示,右边的展示为 null
|
|
5.4.7 右外连接查询
以右表为基准,匹配左边表中的数据
如果能匹配到,展示匹配到的数据
如果匹配不到,右表中的数据正常展示,左边展示为 null
|
|
5.4.8 总结
- 内连接: inner join
- 只获取两张表中,交集部分的数据
- 左外连接: left join
- 以左表为基准,查询左表的所有数据,以及与右表有交集的部分
- 右外连接: right join
- 以右表为基准,查询右表的所有的数据,以及与左表有交集的部分
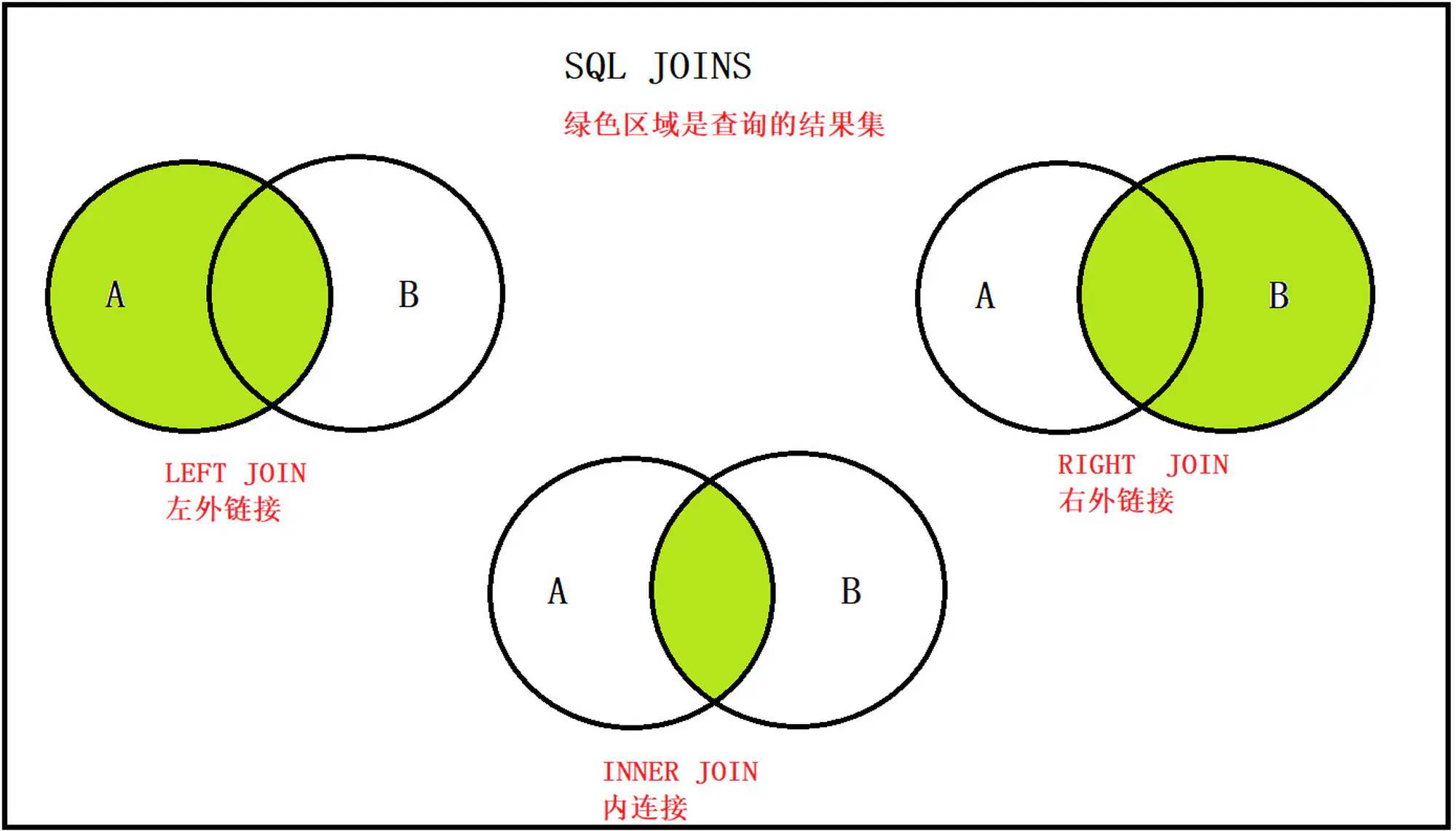
10.多表查询)
5.5 子查询
一条 select 查询语句的结果,作为另一条 select 语句的一部分
|
|
- 特点
- 子查询必须放在小括号中
- 子查询一般作为父查询的查询条件使用
- 分类
- where 型子查询:
- 将子查询的结果,作为父查询的比较条件
- from 型子查询:
- 将子查询的结果,作为 一张表,提供给父层查询使用
- exists 型子查询:
- 子查询的结果是单列多行,类似一个数组,父层查询使用 IN 函数,包含子查询的结果
- where 型子查询:
5.5.1 子查询的结果作为查询条件
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
|
|
5.5.2 子查询的结果作为一张表
SELECT 查询字段 FROM (子查询)表别名 WHERE 条件;
当子查询作为一张表的时候,需要起别名,否则无法访问表中的字段。
|
|
5.5.3 子查询结果是单列多行
子查询的结果类似一个数组,父层查询使用 IN 函数,包含子查询的结果
|
|
5.5.4 子查询小结
- 子查询如果查出的是一个字段(单列),那就在 where 后面作为条件使用
- 子查询如果查询出的是多个字段(多列),就当做一张表使用(要起别名)
6 数据库设计
6.1 数据库设计三范式
- 三范式就是设计数据库的规则
- 为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式
- 满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF) , 其余范式以此类推。一般说来,数据库只需满足第三范式(3NF)就行了
6.1.1 第一范式 1NF
- 原子性,做到列不可拆分
- 第一范式是最基本的范式。数据库表里面字段都是单一属性的,不可再分,如果数据表中每个字段都是不可再分的最小数据单元,则满足第一范式。
6.1.2 第二范式 2NF
- 在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关。
- 一张表只能描述一件事。
6.1.3 第三范式 3NF
- 消除传递依赖表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
6.2 数据库设计反三范式
- 反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能
- 设计数据库时,某一个字段属于一张表,但它同时出现在另一个或多个表,且完全等同于它在其本来所属表的意义表示,那么这个字段就是一个冗余字段
- 浪费存储空间,节省查询时间(以空间换时间)
6.3 总结
创建一个关系型数据库设计,我们有两种选择
- 尽量遵循范式理论的规约,尽可能少的冗余字段,让数据库设计看起来精致、优雅、巧妙
- 合理的加入冗余字段这个润滑剂,减少 join ,让数据库执行性能更高,速度更快。