JDK、Hadoop、Hive 的多版本切换
目录
JDK、Hadoop、Hive 的多版本切换
1 背景
有时候需要测试不同版本下的功能,如果能够多版本切换,就不用创建多个虚拟机了。
本文记录在 CentOS7 环境下,JDK、Hadoop、Hive 的多版本安装和切换。
使用的版本如下:
- openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
- openjdk-11+28_linux-x64_bin.tar.gz
- jdk-8u301-linux-x64.tar.gz
- jdk-11.0.12_linux-x64_bin.tar.gz
- hadoop-2.9.2.tar.gz
- hadoop-3.3.1.tar.gz
- apache-hive-2.3.9-bin.tar.gz
- apache-hive-3.1.2-bin.tar.gz
下载、上传过程略过
安装包统一放在 /opt/lagou/tarball 这个目录下面
软件统一安装在 /opt/lagou/run 这个目录下面
2 JDK 的安装和多版本切换
-
解压
-
1 2 3 4 5 6 7 8 9 10 11 12tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz && \ tar -zxvf openjdk-11+28_linux-x64_bin.tar.gz && \ tar -zxvf jdk-8u301-linux-x64.tar.gz && \ tar -zxvf jdk-11.0.12_linux-x64_bin.tar.gz ls mv jdk1.8.0_301/ ../run/oracle_jdk1.8.0_301/ && \ mv jdk-11.0.12/ ../run/oracle_jdk-11.0.12/ && \ mv java-se-8u41-ri/ ../run/open_jdk-8u41/ && \ mv jdk-11/ ../run/open_jdk-11/ ls ../run
-
-
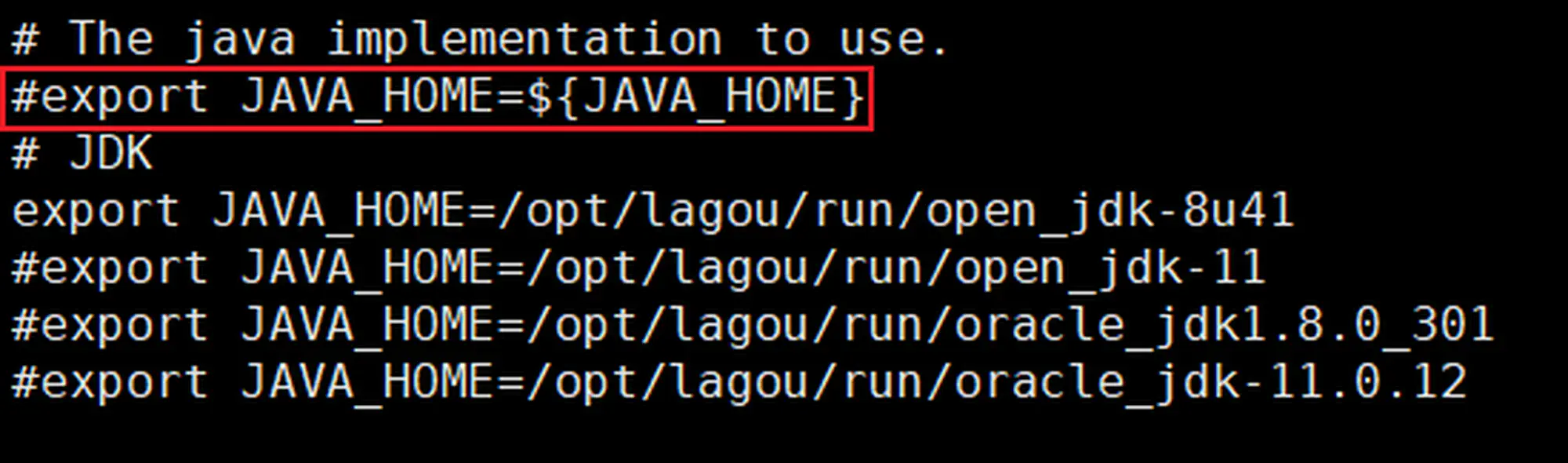
配置 JDK 环境变量
-
编辑:
nano /etc/profile,添加如下内容 -
1 2 3 4 5 6 7 8# JDK export JAVA_HOME=/opt/lagou/run/open_jdk-8u41 #export JAVA_HOME=/opt/lagou/run/open_jdk-11 #export JAVA_HOME=/opt/lagou/run/oracle_jdk1.8.0_301 #export JAVA_HOME=/opt/lagou/run/oracle_jdk-11.0.12 export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin
-
-
切换方法(修改环境变量)
- 需要哪一个版本,就打开(取消注释)这个版本的这一行,把其他几行注释掉
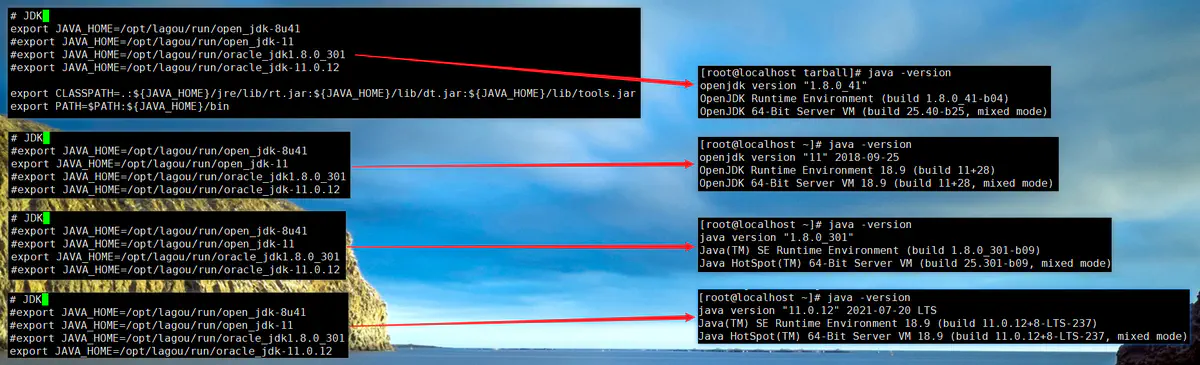
JDK、Hadoop、Hive多版本切换( 1.JDK)- 改完后重新登录
-
注意
- JDK 的版本切换,只是用
source /etc/profile命令刷新环境变量并不能成功切换,要logout,重新登录 - 如果有任何 java 进程在跑,也不能切换成功
- 有一些应用(比如下文中的 Hadoop ),如果不是使用系统的环境变量,而是在自有的配置文件中指定了 JDK 目录,也不能通过这种方式切换其使用的 JDK 版本,要修改对应的配置文件
- JDK 的版本切换,只是用
3 Hadoop 的安装和多版本切换
3.1 解压,配置 Hadoop 环境变量
-
1 2 3 4 5 6 7tar -zxvf hadoop-2.9.2.tar.gz && tar -zxvf hadoop-3.3.1.tar.gz ls mv hadoop-2.9.2/ ../run/hadoop-2.9.2/ mv hadoop-3.3.1/ ../run/hadoop-3.3.1/ nano /etc/profile -
1 2 3 4 5 6# Hadoop export HADOOP_HOME=/opt/lagou/run/hadoop-2.9.2 #export HADOOP_HOME=/opt/lagou/run/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin -
1 2source /etc/profile hadoop version
3.2 配置 2.9.2 版的 Hadoop
-
修改配置文件
-
这里就是简单让 Hadoop 跑起来的单节点部署模式
-
修改 3 个 … _env.sh 脚本,配置 JDK 目录
-
1 2 3 4 5cd $HADOOP_HOME/etc/hadoop nano hadoop-env.sh nano mapred-env.sh nano yarn-env.sh -
1 2 3 4 5# JDK export JAVA_HOME=/opt/lagou/run/open_jdk-8u41 #export JAVA_HOME=/opt/lagou/run/open_jdk-11 #export JAVA_HOME=/opt/lagou/run/oracle_jdk1.8.0_301 #export JAVA_HOME=/opt/lagou/run/oracle_jdk-11.0.12 -
其中,hadoop-env.sh 脚本中原有的 JAVA_HOME 要注释掉
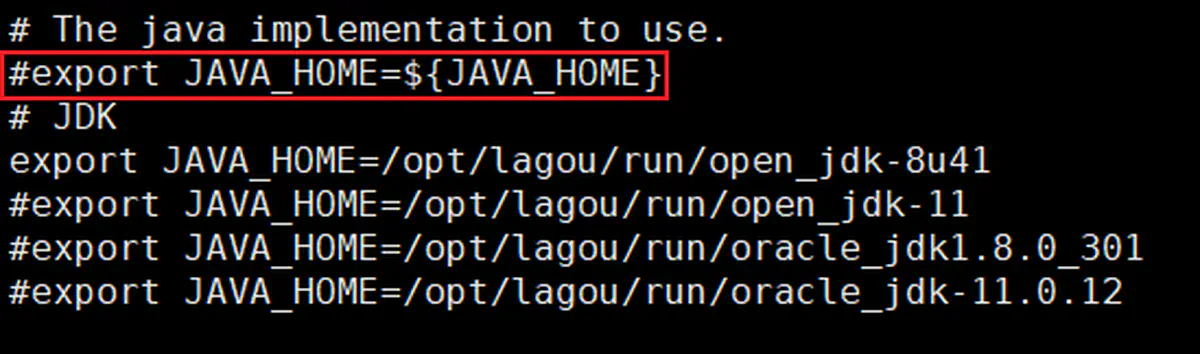
JDK、Hadoop、Hive多版本切换( 2.hadoop-env.sh)
-
-
nano core-site.xml-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/lagou/software_run/hadoop-2.9.2/data/tmp</value> </property> </configuration>
-
-
1 2cp mapred-site.xml.template mapred-site.xml nano mapred-site.xml-
1 2 3 4 5 6 7 8 9<configuration> <!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
-
nano yarn-env.sh-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17<configuration> <!-- Site specific YARN configuration properties --> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
-
-
-
启动测试
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26# 首次启动之前,执行 NN 的格式化 hadoop namenode -format # 启动 start-dfs.sh start-yarn.sh # 测试 HDFS mkdir -p ~/test && cd ~/test ls touch test1.txt echo HelloWorld! > test1.txt hdfs dfs -put test1.txt / hdfs dfs -ls / hdfs dfs -cat /test1.txt # HelloWorld! # 上传一部英文小说,测试 MR hdfs dfs -mkdir -p /wcinput hdfs dfs -put the_little_prince.txt /wcinput hadoop jar /opt/lagou/run/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput hdfs dfs -ls /wcoutput hdfs dfs -tail /wcoutput/part-r-00000
-
-
关闭 Hadoop
-
1 2stop-dfs.sh stop-yarn.sh
-
3.3 配置 3.3.1 版的 Hadoop
-
切换版本
-
nano /etc/profile -
1 2 3 4 5 6# Hadoop #export HADOOP_HOME=/opt/lagou/run/hadoop-2.9.2 export HADOOP_HOME=/opt/lagou/run/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin -
改完后重新登录
-
-
修改配置文件
-
nano hadoop-env.sh-
1 2 3 4 5 6 7 8 9 10 11 12# JDK export JAVA_HOME=/opt/lagou/run/open_jdk-8u41 #export JAVA_HOME=/opt/lagou/run/open_jdk-11 #export JAVA_HOME=/opt/lagou/run/oracle_jdk1.8.0_301 #export JAVA_HOME=/opt/lagou/run/oracle_jdk-11.0.12 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
-
-
nano core-site.xml-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/lagou/run/hadoop-3.3.1/data/tmp</value> </property> </configuration>
-
-
nano mapred-site.xml-
1 2 3 4 5 6 7 8 9<configuration> <!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
-
1 2 3 4# 查看 classpath hadoop classpath nano yarn-env.sh-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20<configuration> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.application.classpath</name> <value>/opt/lagou/run/hadoop-3.3.1/etc/hadoop:/opt/lagou/run/hadoop-3.3.1/share/hadoop/common/lib/*:/opt/lagou/run/hadoop-3.3.1/share/hadoop/common/*:/opt/lagou/run/hadoop-3.3.1/share/hadoop/hdfs:/opt/lagou/run/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/opt/lagou/run/hadoop-3.3.1/share/hadoop/hdfs/*:/opt/lagou/run/hadoop-3.3.1/share/hadoop/mapreduce/*:/opt/lagou/run/hadoop-3.3.1/share/hadoop/yarn:/opt/lagou/run/hadoop-3.3.1/share/hadoop/yarn/lib/*:/opt/lagou/run/hadoop-3.3.1/share/hadoop/yarn/*</value> </property> </configuration>
-
-
-
启动测试
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23# 首次启动之前,执行 NN 的格式化 hadoop namenode -format # 启动 start-dfs.sh start-yarn.sh # 测试 HDFS cd ~/test ls hdfs dfs -put test1.txt / hdfs dfs -ls / hdfs dfs -cat /test1.txt # HelloWorld! # 测试 MR hdfs dfs -mkdir -p /wcinput hdfs dfs -put the_little_prince.txt /wcinput hadoop jar /opt/lagou/run/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /wcinput /wcoutput hdfs dfs -ls /wcoutput hdfs dfs -tail /wcoutput/part-r-00000
-
注意
- 切换 Hadoop 运行时使用的 JDK 版本,需要修改 Hadoop 自身的配置文件
- 切换 Hadoop 版本,需要
logout,重新登录
4 Hive 的安装和多版本切换
-
解压,配置环境变量
-
1 2 3 4 5 6 7tar -zxvf apache-hive-2.3.9-bin.tar.gz && tar -zxvf apache-hive-3.1.2-bin.tar.gz ls mv apache-hive-2.3.9-bin/ ../run/hive-2.3.9/ mv apache-hive-3.1.2-bin/ ../run/hive-3.1.2/ nano /etc/profile -
1 2 3 4 5# Hive export HIVE_HOME=/opt/lagou/run/hive-2.3.9 #export HIVE_HOME=/opt/lagou/run/hive-3.1.2 export PATH=$PATH:$HIVE_HOME/bin -
1 2source /etc/profile hive --version
-
-
准备数据库
-
MySQL的安装(略过)
-
进入 MySQL-CLI:
mysql -uroot -p -
1 2 3 4 5 6 7 8 9 10 11#创建两个库 show databases; create database hivemetadata239; create database hivemetadata312; show databases; #共用一个用户 CREATE USER 'hive'@'%' IDENTIFIED BY '12345678'; GRANT ALL ON hivemetadata239.* TO 'hive'@'%'; GRANT ALL ON hivemetadata312.* TO 'hive'@'%'; FLUSH PRIVILEGES;
-
-
修改(新建)配置文件
-
nano $HIVE_HOME/conf/hive-site.xml -
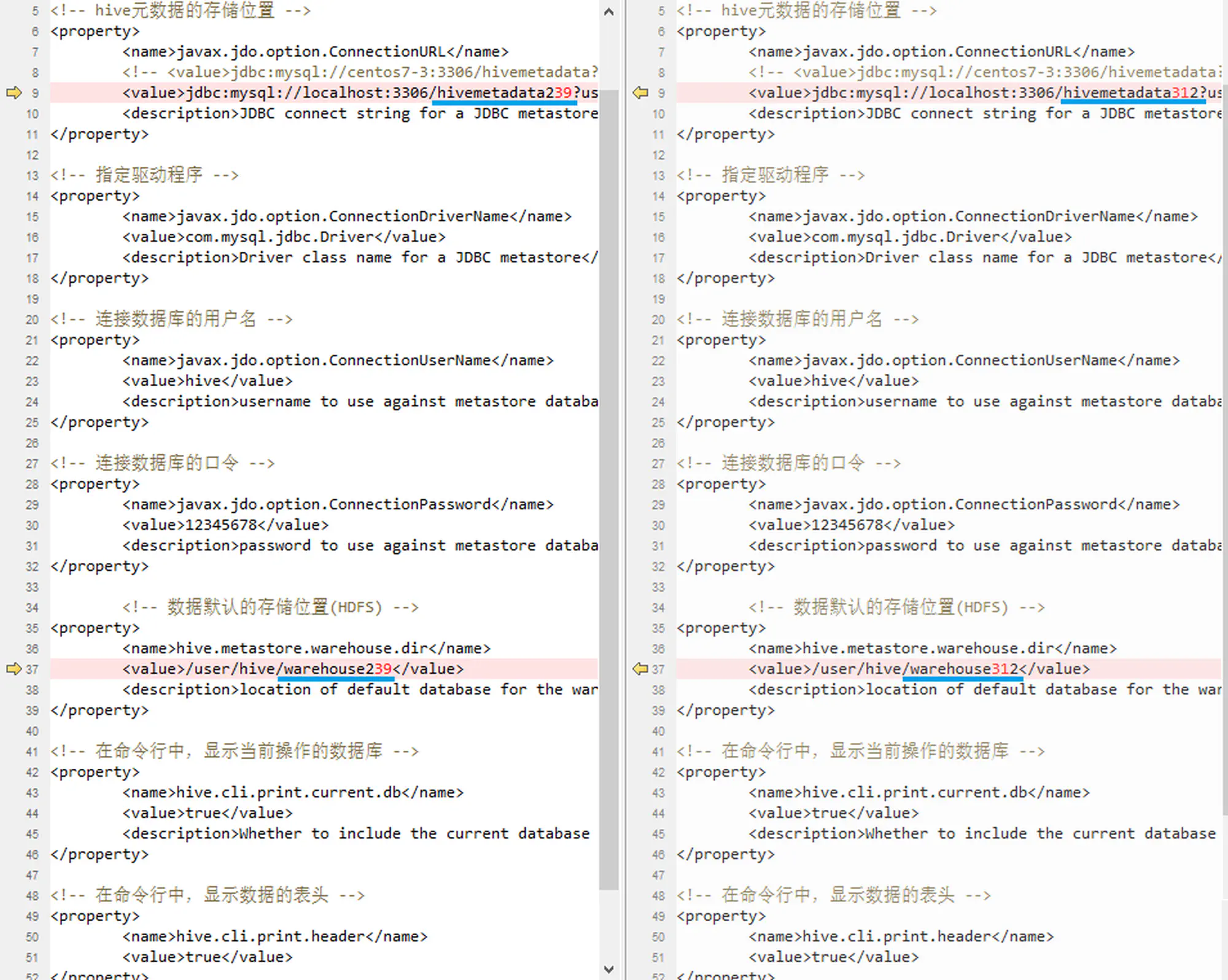
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- hive元数据的存储位置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <!-- <value>jdbc:mysql://centos7-3:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false</value> --> <value>jdbc:mysql://localhost:3306/hivemetadata239?useUnicode=true&characterEncoding=utf8&useSSL=false</value> <description>JDBC connect string for a JDBC metastore</description> </property> <!-- 指定驱动程序 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <!-- 连接数据库的用户名 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <!-- 连接数据库的口令 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>12345678</value> <description>password to use against metastore database</description> </property> <!-- 数据默认的存储位置(HDFS) --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse239</value> <description>location of default database for the warehouse</description> </property> <!-- 在命令行中,显示当前操作的数据库 --> <property> <name>hive.cli.print.current.db</name> <value>true</value> <description>Whether to include the current database in the Hive prompt.</description> </property> <!-- 在命令行中,显示数据的表头 --> <property> <name>hive.cli.print.header</name> <value>true</value> </property> </configuration> -
2.3.9 和 3.1.2 的配置文件相同,只需要该数据库名,和在 HDFS 中的存储位置

JDK、Hadoop、Hive多版本切换( 3.二者差异)
-
-
将
mysql-connector-java-5.1.49-bin.jarjar 包上传至$HIVE_HOME/lib目录- 2.3.9 和 3.1.2 一样
-
初始化 hive 元数据库
-
1schematool -dbType mysql -initSchema -
2.3.9 和 3.1.2 一样
-
-
测试
-
进入 Hive-CLI :
-
1 2 3show databases; create database test1; show databases; -
2.3.9 和 3.1.2 一样
-
-
切换版本
- HIVE 切换版本比较方便,直接修改环境变量,刷新环境变量就可以