
检查硬盘的健康状态
目录
检查硬盘的健康状态
1 背景
信息时代,或者说对于计算机来说,最重要的就是数据,没有数据,一切都是空谈,丢失了数据,就是 IT 灾难。
硬盘(及其他存储媒介)作为存储数据的载体,其健康状态直接关系着数据存储安全。
细数本 X 曾经坏过的硬盘
- 借用某同学电脑的时候,把他的一块 80G 硬盘玩坏了
- 损失早年一些游戏、软件安装包,现在再也找不到了,即使找到也是经过各种加料的
- 一块 160G 硬盘
- 相对幸运的是,那时候已经知道留意硬盘健康状态了
- 只损失了一些电影,但是很多冷门文艺片,现在也是找不回来了
- 一块 2G U盘,在网吧被 “前面板接错线的 USB 接口” 烧了(极可能是某些人有意为之)
- 当时 U盘插上去没反应,拔的时候发烫,我还傻傻地把一块 40G 移动硬盘插上去试,万幸,移动硬盘只烧了控制板
- 那几年自己没电脑,就靠着一个小 U盘存活
- 那一次数据丢失导致少量相当于直接切断的影响
- 还曾经在工作中经历过一次比较严重的灾难
- 接手某应用系统服务器。
- 因为没有正式交接,同时还有另一位 “领导” 、一位应用系统管理员,在管理这台设备;并且当时工作很忙,刚接手我就没去看这台设备。
- 结果还没出一周,挂了😑
- 阵列卡挂了……
- 请示完马上联系数据恢复服务
- 工程师上门一看,一脸哀怨:不止阵列卡挂了,四块盘两块有坏道
- 100%恢复是不可能了,只能看看是否能把数据库文件恢复出来(应用代码在应用系统管理员那边还有)
- 万幸,数据库恢复了
- 灾后重建
- 一方面,当时本 X 直接用虚拟机搭了临时服务器(还好负载不高,能扛住),恢复服务,业务只中断了24小时
- 另一方面,那台组装的古董服务器年事已高,管理层同意买新的(切记服务器至少要买 “热盘” 的,热不热电都是其次)
- 后来不到两个月这台新服务器就有一块盘闪红灯😑
- 还好本 X 每天检查 + 巡检,及时发现
- 又因为是 “热盘” 的,直接更换,避免了又一次灾难
- 事后了解到
- 那台服务器之前就宕机过,而且不止一次
- 他们直接跳过了开机的警告,继续使用……😑
- 接手某应用系统服务器。
- 另外还有一次,把坏道盘发放出去使用了
- (这个世界有很多奇怪的人,就是过去完全没有交集,初见也会给你挖坑)
- 万幸,也是不能 100% 恢复,但恢复出必需的文件(全在桌面😑)
2 S.M.A.R.T.
那么,这种问题如何解决呢?
总不能每天都扫描一次硬盘吧?多伤啊?
幼稚!业界早在1992年就有了相对成熟的解决方案,早在1995年就制定了行业标准。
S.M.A.R.T. (可简称为:SMART)全称为“Self-Monitoring Analysis and Reporting Technology”,即“自我监测、分析及报告技术”,是一种自动的硬盘状态检测与预警系统和规范。通过在硬盘硬件内的检测指令对硬盘的硬件如磁头、盘片、马达、电路的运行情况进行监控、记录并与厂商所设定的预设安全值进行比较,若监控情况将要或已超出预设安全值的安全范围,就可以通过主机的监控硬件或软件自动向用户作出警告并进行轻微的自动修复,以提前保障硬盘数据的安全。1
对用户而言,就是通过检查 SMART 状态,可以了解硬盘大致的健康状态,从而提前发现隐患,及时更换硬盘,避免灾难发生、数据丢失。
3 如何检查 SMART
对于使用了阵列卡的主机,由阵列卡接管硬盘的健康状态,在操作系统中不能直接读取 SMART ,通过 “开机自检” 、服务器 “远控卡” 和 “集中管理平台” ,可以看到硬盘的健康状态。
对个人电脑而言,推荐使用 “CrystalDiskInfo” (开源免费),和测评界常用的 “CrystalDiskMark” 是亲兄弟
- 下载、解压、运行
检查硬盘的健康状态( 1.下载、解压、运行)
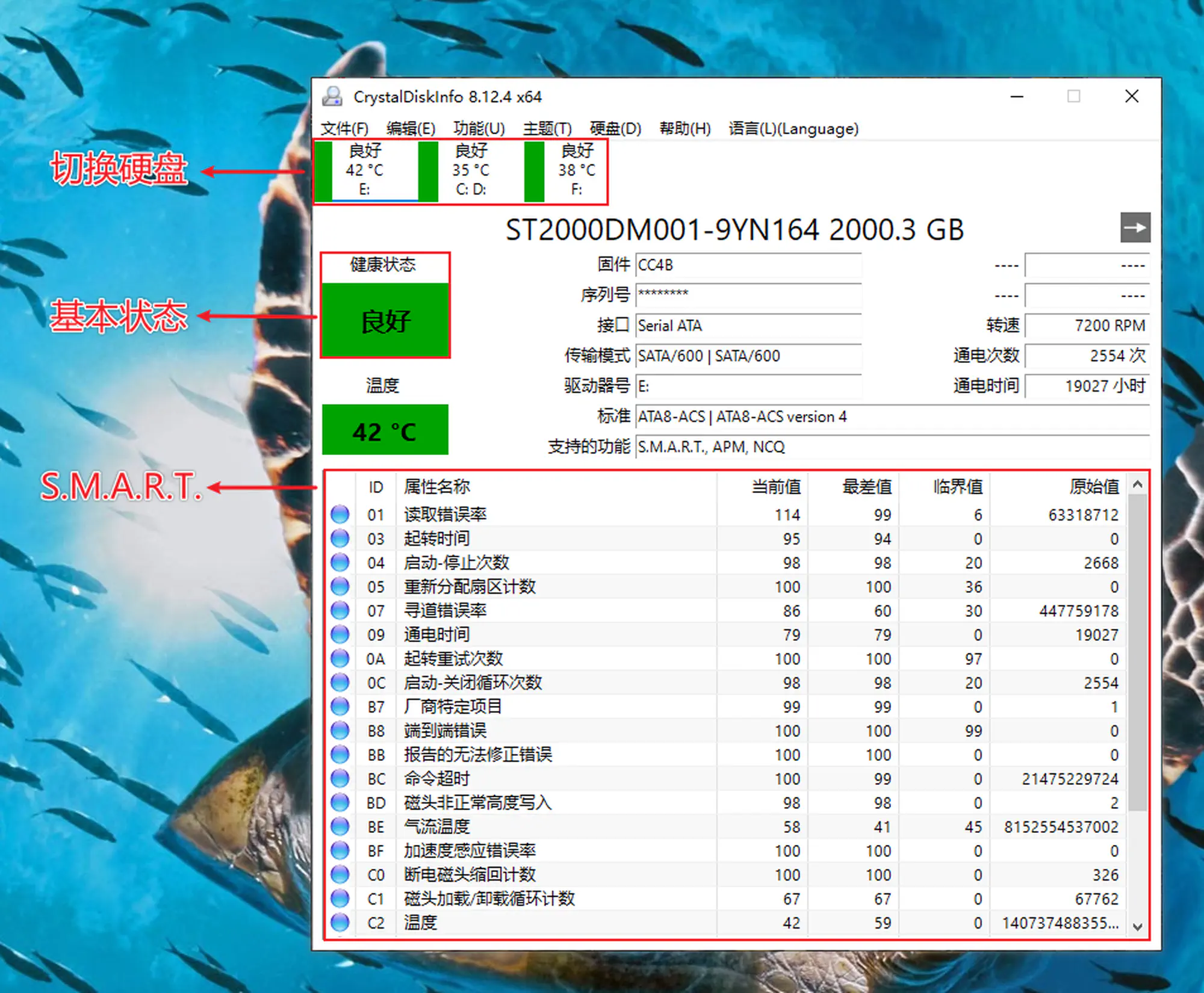
- 程序主界面,本 X 习惯使用 FlatSquare 界面风格(软件作者是个很二次元的日本人,除了标准界面还提供了一些二次元主题)
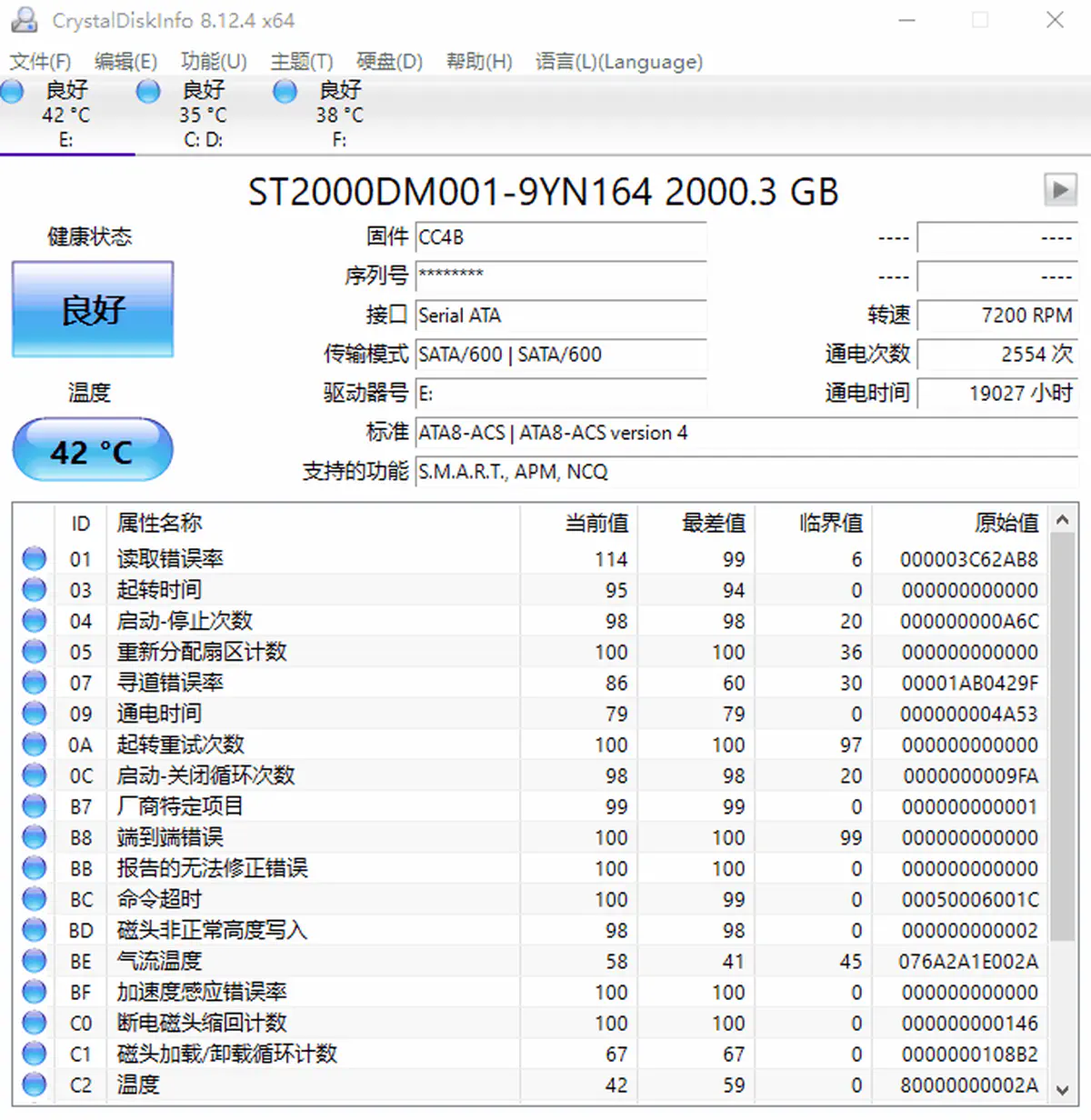
检查硬盘的健康状态( 2.程序主界面)
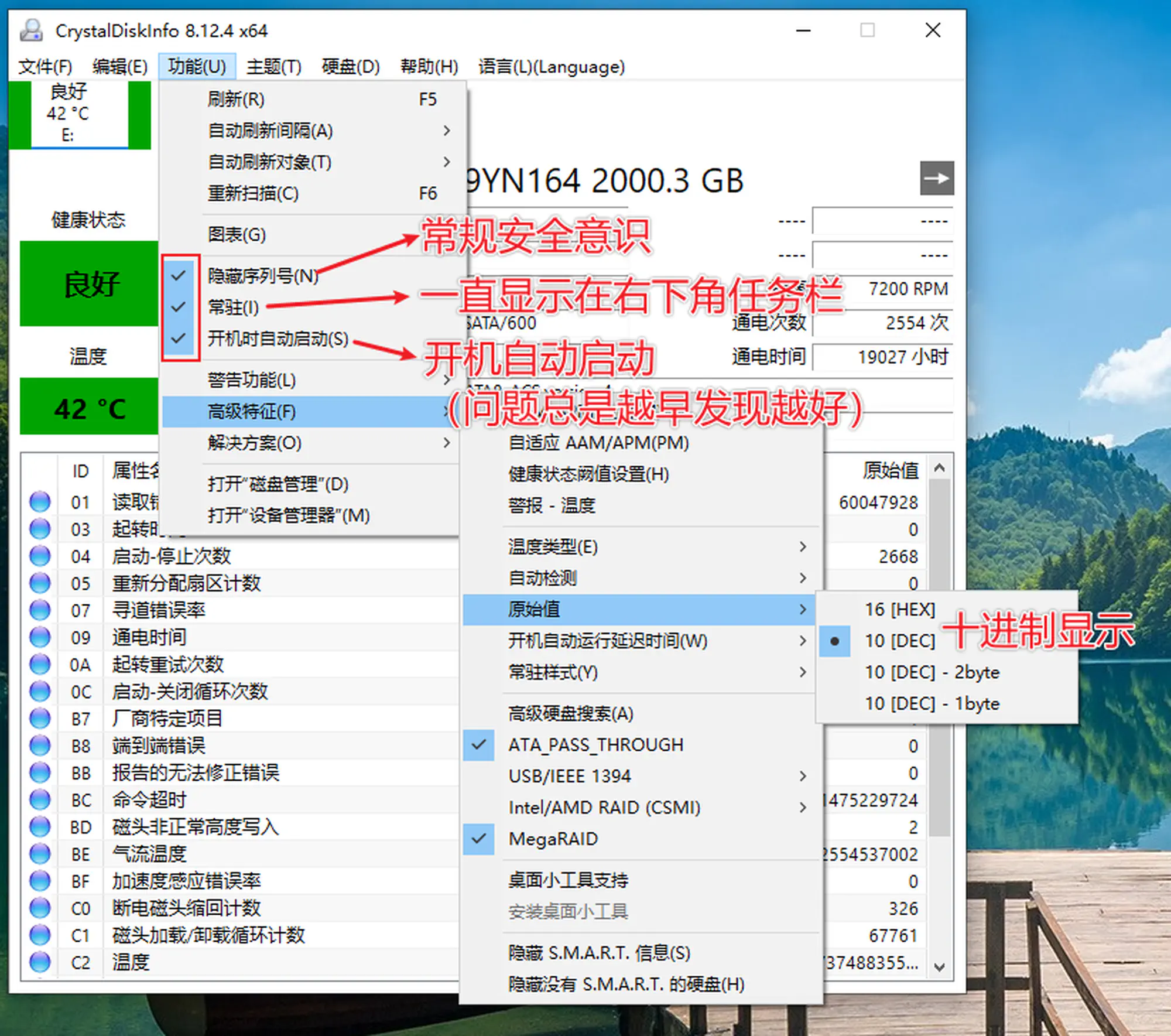
- 推荐设置
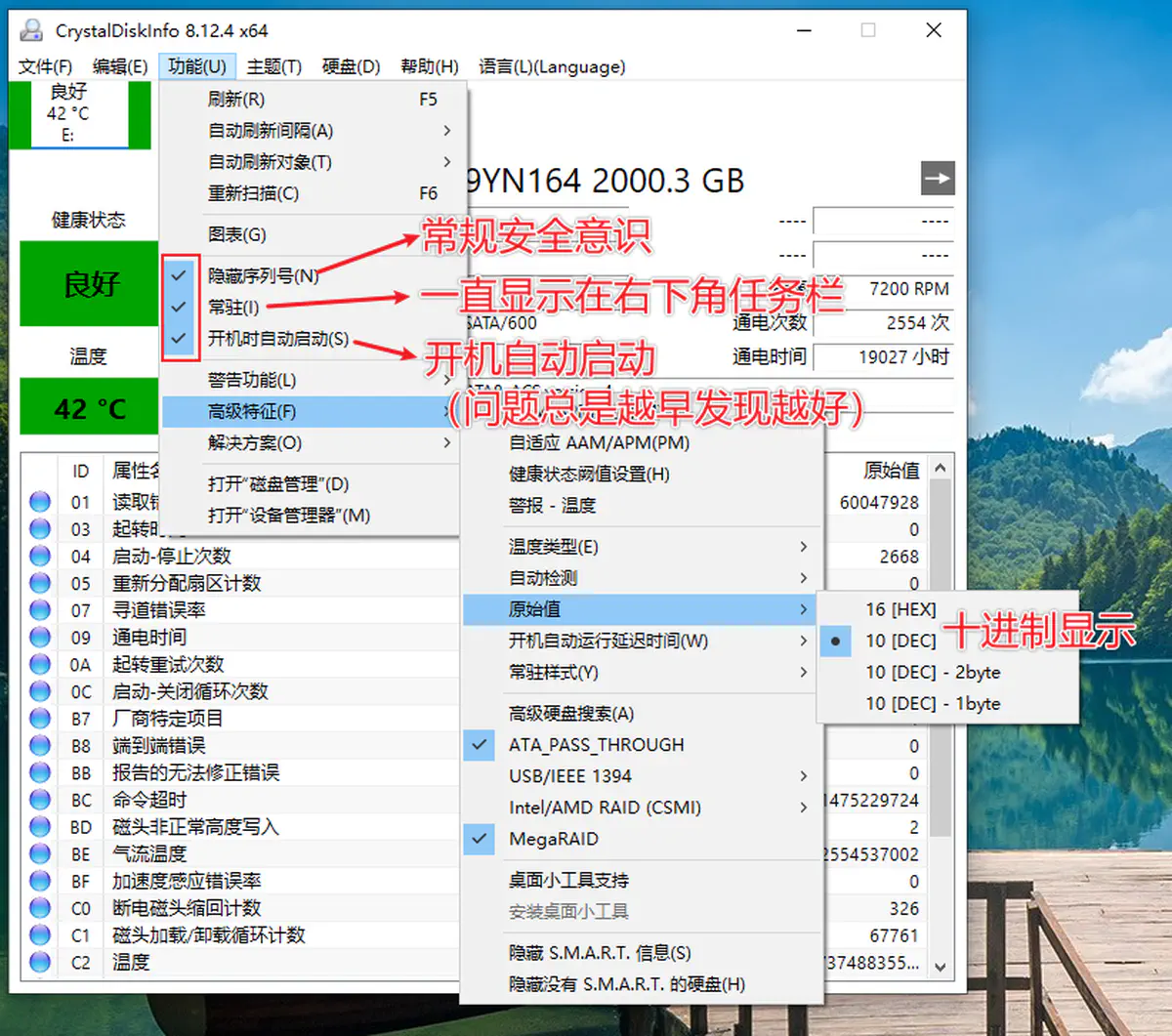
检查硬盘的健康状态( 3.推荐设置)- 不用担心性能问题,这软件使用内存不到 10M
- 也不用担心安全问题,这软件不联网;而且是开源的,实在不放心可以自己拿源码编译
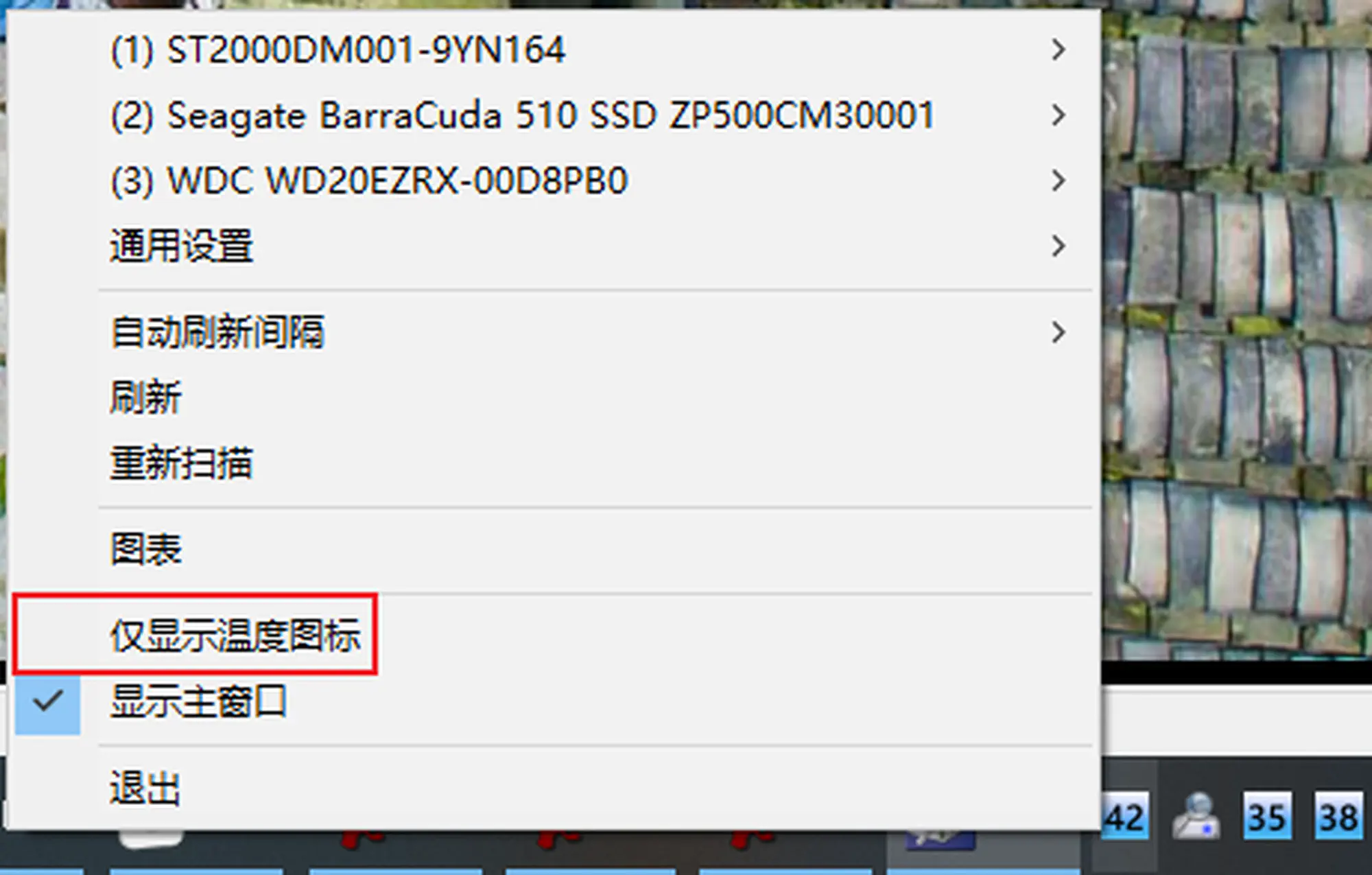
- 任务栏图标右键,勾选此项,可以减少一个图标
检查硬盘的健康状态( 4.任务栏图标)
- 简单说明
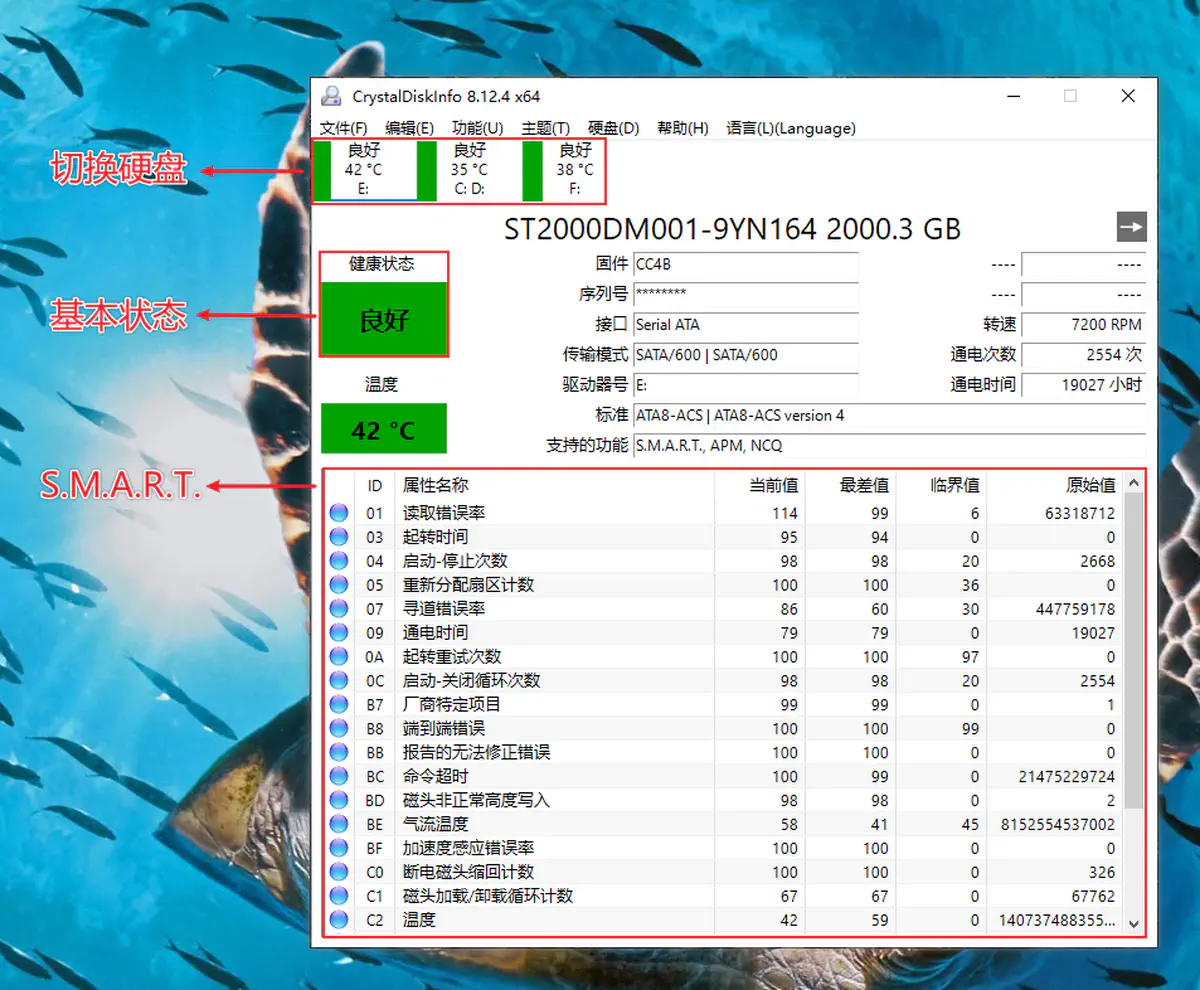
检查硬盘的健康状态( 5.简单说明)
- 部分主板也支持 S.M.A.R.T. 检查,在开机自检过程中进行
- 对于 NAS 用户,因为针对个人用户的 NAS 产品,很多并没有 S.M.A.R.T. 报警功能,所以
- 一定要正确配置报警功能,并定时检查该功能是否正常工作
- 或者周期性地,手动登录后台检查
- 如果你的 NAS 即没有报警功能,后台也没有 S.M.A.R.T. 或健康状态报告,赶 紧 退 货
- 有些人会以为有了阵列就可以高枕无忧,错!磁盘阵列环境下,一样要及时处理隐患,否则一块盘出错,会频繁进行同步、校验、读写……操作,大幅影响性能,甚至把其他盘一起拖坏
4 重要检查项
以下列出比较重要,且能直观地从数值上看出状况的项
4.1 与硬盘坏道相关的项
05- 重新分配扇区计数
- 就是已经损坏,并且(基于备用扇区机制)已经成功把数据转移到备用扇区的计数
C4- 重新分配扇区物理位置事件计数(与坏道有关)
- 西数有这项,希捷没有
- 记录已重映射扇区和可能重映射扇区的事件计数。(不清楚与
05有什么具体不同)
C5- 当前等待中扇区数(状态存疑/不稳定-等待后续判断)
- 就是不稳定扇区,SMART没确诊该扇区损坏,但该扇区状态不稳定,应注意观察
C6- 无法修正的扇区总数
- 记录肯定出错的扇区数量。就是扇区确认损坏,但没能成功转移至备用扇区
- 可能是备用扇区用完了
- 或者就是完完全全读不到该扇区的数据了
一般建议
- 硬盘 SMART 出现
05、c4、c5、c6这几个值异常的时候- 关电脑(给硬盘断电),准备好另外的存储介质,再开机转移数据
- 转移数据过程中切记实时跟踪这几个数值,如继续发生变化,建议断电,请专业人士介入
- 对于已经出现坏道,并完成数据转移的硬盘
- 本着环保 3R 原则: Reduce(减量) Reuse(复用) Recycle(回收),可以采取一些做法尝试回收(其实就是穷😌)
- 使用 MHDD 进行重映射操作
- 将损坏扇区分到一个分区下,并且不是这个分区
- 但经过这么 “修复” 的硬盘,就不要再用来存放重要数据资料了
- 也有不少奸商卖的就是这种盘
- 本着环保 3R 原则: Reduce(减量) Reuse(复用) Recycle(回收),可以采取一些做法尝试回收(其实就是穷😌)
- 现实也存在,这几个 SMART 值出现异常后,硬盘继续正常使用几年的个例
- 与备用扇区的机制有关
- 与坏扇区的读写频率有关
- 与运气有关
- 也有 5 分钟内相关数值增长上千,然后直接挂掉的例子
- 至于最后采取什么样的处理方式,用户应自行评估数据的重要性
4.2 其他重要项
0A- 起转重试次数
- 主轴电机起转重试次数,这个属性存储了关于主轴电机尝试加速到完全可操作速度的次数(意味着主轴电机的第一次启动尝试没有成功)。
- 排除供电问题之后,如果这个数值还会增长,那么,赶紧换盘
- 如果是电机故障导致硬盘不能启动,通常可以通过 “开盘” 恢复数据,就是开盘需要 “无尘” 工作室/台,收费会贵一点
4.3 与使用量相关的项
04、0C- 硬盘通电(启动)次数
09- 硬盘通电时间(一般单位为小时)
这两项可以用来判断硬盘使用了多久
但只能作为参考,有的奸商会修改这些数值
5 其他存储介质
- U盘、存储卡,不支持 SMART
- 做好备份
- 可通过测试读写性能进行推测(性能下降通常就是寿命将近)
- 可使用 H2testw 进行坏块检测(同时测试读写性能)
- 这就真的是完整扫描一次了(正如前文所说,有点伤)
- 还有一些量产工具也提供坏块检测功能
- SSD,支持 SMART
- 但 SSD 存储原理与硬盘有所不同,且各厂家使用的技术,相对硬盘来说也比较多样,这些厂家对各自的 SMART 值定义也不是很开放
- 基本的健康状态用 CrystalDiskInfo 还是可以看出来的
- 不过还是推荐使用各 SSD 厂商开发的配套软件(除了检查 SMART,还有 “重置 Trim ” 等功能)